Operating System Notes
Lecture 1 - Introduction
What is an operating system?
An operating system is a middleware between user programs and system hardware.
| User Programs |
|---|
| OS |
| Hardware: CPU, Memory, Disk, I/O |
An operating system manages hardware: CPU, Main Memory, IO devices (disk, network, card, mouse, keyboard, etc.)
What happens when you run a program? (Background)
A compiler translated high level programs into an executable (“.c” to “a.out”)
The executable contains instructions that the CPU can understand and the program’s data (all numbered with addresses).
Instructions run on CPU: hardware implements an Instruction Set Architecture (ISA).
CPU also consists of a few registers, e.g.,
- Pointer to current instruction (PC)
- Operands of the instructions, memory addresses
To run an exe, the CPU does the following:
- Fetches instruction ‘pointed at’ by PC from memory
- Loads data required by the instructions into registers
- Decodes and executes the instruction
- Stores the results to memory
Most recently used instructions and data are in CPU cache (instruction cache and data cache) for faster access.
What does the OS do?
OS manages CPU
It initializes program counter (PC) and other registers to begin execution. OS provides the process abstraction.
Process: A running program
OS creates and manages processes. Each process has the illusion of having the complete CPU, i.e., OS virtualizes CPU. It timeshares the CPU between processes. It also enables coordination between processes.
OS manages memory
It loads the program executable (code, data) from disk to memory. It has to manage code, data, stack, heap, etc. Each process thinks it has a dedicated memory space for itself, numbers code, and data starting from 0 (virtual addresses).
The operating system abstracts out the details of the actual placement in memory, translates from virtual addresses to real physical addresses.
Hence, the process does not have to worry about where its memory is allocated in the physical space.
OS manages devices
OS helps in reading/writing files from the disk. OS has code to manage disk, network card, and other external devices: device drivers.
Device driver: Talks the language of the hardware devices.
It issues instructions to devices (fetching data from a file). It also responds to interrupt events from devices (pressing a key on the keyboard).
The persistent (ROM) data is organised as a file system on the disk.
Design goals of an operating system
- Convenience, abstraction of hardware resources for user programs.
- Efficiency of usage of CPU, memory, etc.
- Isolation between multiple processes.
History of operating systems
OS started out as a library to provide common functionality across programs. Later, it evolved from procedure calls to system calls.
When a system call is made to run OS code, the CPU executes at a higher privilege level.
OS evolved from running a single program to executing multiple processes concurrently.
Lecture 2 - The Process Abstraction
An operating system provides process abstraction. That is, when you execute a program, the OS creates a process. It timeshares CPU across multiple processes (virtualizing CPU). An OS also has a CPU scheduler that picks one of the many active processes to execute on a CPU. This scheduler has 2 components.
- Policy - It decides which process to run on the CPU
- Mechanism - How to “context-switch” between processes
What constitutes a process?
Every process has a unique identifier (PID) and a memory image - the fragments of the program present in the memory. As mentioned earlier, a memory image has 4 components (code, data, stack, and heap).
When a process is running, a process also has a CPU context (registers). This has components such as program counter, current operands, and stack pointer. These basically store the state of the process.
A process also has File descriptors - pointers to open files and devices.
How does an OS create a process?
Initially, the OS allocates and creates a memory image. It loads the code and data from the disk executable. Then, it makes a runtime stack and heap.
After this, the OS opens essential files (STD IN, STD OUT, STD ERR). Then the CPU registers are initialized, and the PC points to the first instruction.
States of a process
-
A process that is currently being executed in the CPU is Running.
-
Processes that are waiting to be scheduled are Ready. These are not yet executed.
-
Some processes may be in the Blocked state. They are suspended and not ready to run. These processes may be waiting for some event, e.g., waiting for input from the user. They are unblocked once an interrupt is issued.
-
New processes are being created and are yet to run.
-
Dead processes have finished executing and are terminated.
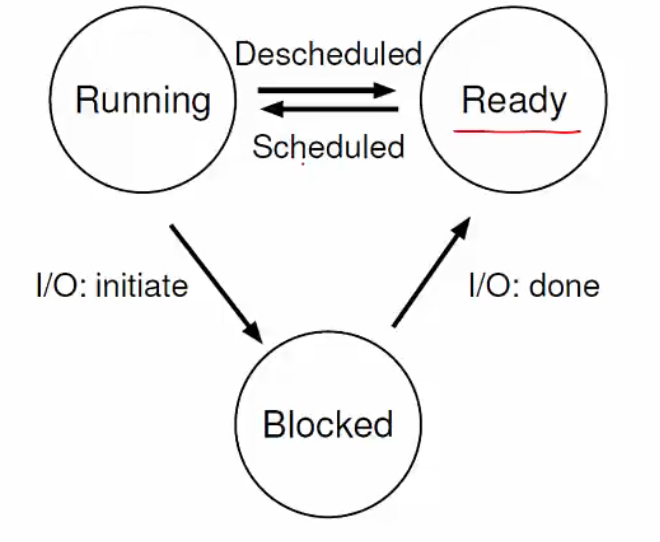
Process State Transitions
When one process is blocked, another process can be executed to utilize the resources effectively. Here is a simple example reflecting this situation.
 |
|---|
| Example: Process States |
OS data structures
An operating system maintains a data structure of all active processes. One such structure is the process control block (PCB). Information about each process is stored in a PCB.
Different Operating Systems might use other names for this structure. PCB is the generic name. All the processes running on the system are stored in a list of PCBs.
A PCB has the following components of a process:
- Process identifier
- Process state
- Pointers to other related processes (parent)
- CPU context of the process (saved when the process is suspended)
- Pointers to memory locations
- Pointers to open files
Lecture 21 - xv6 introduction and x86 background
xv6 is a simple OS used for teaching OS concepts. We shall be using the x86 version of the OS.
An OS enables users to run the processed stored in memory on the CPU.
- It loads the process code/data in main memory.
- CPU fetches, decodes, executes instructions in program code.
- It fetches the process data from memory to CPU registers for faster access during instruction execution (We studied in Arch that memory access is expensive).
- Recently fetched code/data is stored in the CPU in the form of cache for future access.
Memory Image of a process
The memory image of a process consists of
- Compiled code (CPU instructions)
- Global/static variables (memory allocated at compile time)
- Heap (dynamic memory allocation via,
malloc,newetc) that grows (up) on demand. - Stack (temporary storage during function calls, e.g., local variables) that usually grows “up” towards lower addresses. It shrinks “down” as memory is freed (exiting function call).
- Other things like shared libraries.
Every instruction/data has an address, used by the CPU to fetch/store (Virtual addresses managed by OS). Consider the following example
int *iptr = malloc(sizeof(int))
Here, iptr itself is on stack but it points to 4 bytes (size of int) in the heap.
x86 registers
Registers are a small space for data storage with the CPU. Every CPU architecture has its set of registers used during computation. The names of these registers vary across different architectures. These are the common types of registers:
- General purpose registers - stores data during computations (
eax, ebx, ecx, edx, esi, edi). - Pointers to stack locations - base of stack (
ebp) and top of stack (esp). - Program counter or instruction pointer (
eip) - Next instruction to execute. - Control registers - Hold control information or metadata of a process (e.g.,
cr3has pointer to page table of the process). A page table helps the OS to keep track of the memory of the process. - Segment registers (
cs, ds, es, fs, gs, ss) - information about segments (related to memory of process).
x86 Instructions
Every CPU can execute a set of instructions defined in its ISA. The compiled code is written using this ISA so that the CPU can execute these instructions. Here are some common instructions used:
- Load/store -
mov src, dst(AT&T syntax - usingsrcbeforedst)-
mov %eax, %ebx- copy contents ofeaxtoebx -
mov (%eax), %ebx- copy contents at the address ineaxintoebx -
mov 4(%eax), %ebx- copy contents stores at offset of 4 bytes from address stored ateaxintoebx
-
- Push/pop on stack - changes
esp-
push %eax- push contents ofeaxonto stack, updateesp -
pop %eax- pop top of stack ontoeax, updateesp
-
-
jmpsetseipto a specified address -
callto invoke a function,retto return from a function - Variants of above (
movw, pushl) for different register sizes.
Privilege Levels
x86 CPUs have multiple privilege levels called rings (0 to 3). Ring 0 has the highest privilege and OS code runs at this level. Ring 3 has the lowest privilege and user code runs at this level.
There are two types of instructions - privileged and unprivileged. Privileged instructions perform sensitive operations which ideally should not be performed by user programs. These can be executed by the CPU only when running at the highest privilege level (ring 0) .
For example, writing into cr3 register (setting page table) is a privileged instruction. We don’t want a user manipulating memory of another process. instructions to access I/O devices is also privileged.
Unprivileged instructions can be run at lower privilege levels.
Even ring 0?
For example, user code running at a lower privilege level can store a value into a general purpose register.
When a user required OS services (system calls), the CPU moves to higher privilege level and executes OS code that contains privileged instructions. User code cannot invoke privileged instructions directly.
Function calls and the stack
Local variables and arguments are stored on stack for the duration of a function call. When a function is called:
- Arguments are pushed onto the stack.
-
call function- pushes the return address on stack and jumps to function. That is,eipshifts from top of stack to function implementation. - Local variables are allocated on stack
- Function code is executed
-
ret- instruction pops return address,eipgoes back to the old value.
What exactly is happening above?
In this way, stack acts as a temporary storage for function calls.
Before making a function call, we may have to store values of some registers. This is because, registers can get clobbered during a function call.
- Some registers are saved on stack by caller before invoking the function (caller save registers). The function code (callee) can freely change them, and the caller restores them later.
- Some registers are saved by callee, and are restored after function ends (callee save registers). Caller expects them to have same value on return.
- Return value stored in
eaxregister by callee (one of caller save registers)
All of the above is automatically done by the C compiler (C calling convention). Every language has a calling convention that decides which registers have to be classified as caller and callee.
Caller and Callee both store the registers?
Timeline of a function call is as follows (Note. Stack grows up from higher to lower addresses):
- Caller save registers are pushed (
eax, ecx, edx) - Arguments of the function are pushed in reverse order onto the stack
- The return address or the old
eipis pushed on stack by thecallinstruction - The old
ebpis also pushed onto the stack - Set
ebpto the current top of the stack (base of new “stack frame” of the function) - Push local variables and callee save registers (
ebx, esi, edi).espautomatically goes up as you push things onto the stack. - The function is executed.
- After the function execution, the current stack frame is popped to restore the old
ebp. - The return address is popped and
eipis restored by theretinstruction.

Stack pointers: ebp stores the address of base of the current stack frame and esp stores the address of current top of stack. This way, function arguments are accessible from looking under the stack base pointer.
C vs. assembly for OS code
Most of xv6 is in C! The assembly code is automatically generated by the compiler (including all the stack manipulations for function calls).
However, small parts of the OS are in assembly language. This is because, the OS needs more controls over what needs to be done in some situations. For example, the logic of switching from stack of one process to stack of another cannot be written in a high-level language.
Therefore, basic understanding of x86 assembly language is required to follow some nuances of xv6 code.
More on CPU hardware
Some aspects of CPU hardware that are not relevant to studying OS:
- CPU cache - CPU stores recently fetched instructions and data in multiple levels of cache. The operating system has no visibility or control intro the CPU cache.
- Hyper-threading - A CPU core can run multiple processed concurrently via hyper-threading. From an OS perspective, 4-core CPU with 2 hyper-threads per core, and 8-core CPU with no hyper-threading will look the same, even though the performance may differ. The OS will schedule processes in parallel on the 8 available processors.
Lecture 22: Processes in xv6
The process abstraction
The OS is responsible for concurrently running multiple processes (on one or more CPU cores/processors)
- Create, run, terminate a process
- Context switch from one process to another
- Handle any events (e.g., system calls from process)
OS maintains all information about an active process in a process control block (PCB)
- Set of PCBs of all active processes is a critical kernel data structure
- Maintained as part of kernel memory (part of RAM that stores kernel code and data, more on this later)
PCB is known by different names in different OS
-
structprocin xv6 -
task_structin Linux
PCB in xv6: struct proc
The different states of a process in xv6 (procstate) are given by UNUSED, EMBRYO (new), SLEEPING (blocked), RUNNABLE (ready), RUNNING, ZOMBIE (dead)
The struct proc has
- Size of the process
- Pointer to the apge table
- Bottom of the kernel stack for this process
- Process state
- Process ID
- Parent process
- Pointer to folder in which process is running
- Some more stuff which we will study later
Kernel Stack
Register state (CPU context) is saved on user stack during the function calls to restore/resume later. Likewise, the CPU context is stored on kernel stack when process jumps into OS to run kernel code.
We use a separate stack because the OS does not trust the user stack. It is a separate area of memory per process within the kernel, not accessible by regular user code. It is linked from struct proc of a process.
List of open files
Array of pointers to open files (struct file has info about the open file)
- When user opens a file, a new entry is created in this array, and the index of that entry is passed as a file descriptor to user
- Subsequent read/write calls on a file use this file descriptor to refer to the file
-
First 3 files (array indices 0,1,2) open by default for every process: standard input, output and error
- Subsequent files opened by a process will occupy later entries in the array
Page table
Every instruction or data item in the memory image of process has an address. Page table of a process maintains a mapping between the virtual addresses and physical addresses.
Process table (ptable) in xv6
It has a lock for protection. It is an array of all processes. Real kernels have dynamic-sized data structures. However, xv6 being a dummy OS, has a static array.
A CPU scheduler in the OS loops over all runnable processes, picks one, and sets it running on the CPU.
Process state transtition examples
A process that needs to sleep will set its state to SLEEPING and invoke scheduler.
A process that has run for its fair share will set itself to RUNNABLE and invoke Scheduler. The Scheduler will once again find another RUNNABLE process and set it to RUNNING.
Live Session 1
- Real memory is less than virtual memory. It is easier to let the process think it has the whole memory rather than telling it how much memory it exactly has.
- Memory for Global variables and Function variables is allocated once! We don’t know how many times each function will be called. Therefore, we just assign it once and use the allocated space for repeated calls.
- We have caller and callee registers for storing existing computations in the registers before a function call. We can’t have only one set (callee or caller) store all these values due to some subtle reasons. A caller save register would have to pass some arguments. A callee save register would have to return some arguments. To avoid all this, we have a separate set of caller and callee registers.
- “Only one process can run on a core at any time”. Basically that the OS sees the processor as two different cores in hyper-threading. Therefore, it can run a single process on a core.
- xv6 is primarily written in C. If we need an OS to compile and run a program, how do we run xv6? Whenever you boot a system with an OS, you use an existing OS to build the binaries for the needed OS. Then, you run the binary to run the OS. To answer the chicken and egg problem, someone might’ve written an OS in assembly code initially.
- OS keeps track of locations of memory images using page tables.
- Virtual addresses of an array will be contiguous, but the OS may not allocate contiguous memory.
- When we print the address of a pointer, we get the virtual address of the variable. Exposing the real address is a security risk.
Lecture 3 - Process API
We will discuss the API that the OS provides to create and manage processes.
What is the API?
So, the API refers to the functions available to write user programs. The API provided by the OS is a set of system calls. Recall, a system call is like a function call, but it runs at a higher privilege level. System calls can perform sensitive operations like access to hardware. Some “blocking” system calls cause the process to be blocked and unscheduled (e.g., read from disk).
Do we have to rewrite programs for each OS?
No, we don’t. This is possible due to the POSIX API. This is a standard set of system calls that OS must implement. Programs written to the POSIX API can run on any POSIX compatible OS. Almost every modern OS has this implemented, which ensures program portability. Program language libraries hide the details of invoking system calls. This way, the user does not have to worry about explicitly invoking system calls.
For ex, the printf function in the C library calls the write system call to write to the screen.
Process related system calls (in Unix)
The most important system call to create a process is the fork() system call. It creates a new child process. All processes are created by forking from a parent. The init process is the ancestor of all processes. When the OS boots up, it creates the init process.
exec() makes a process execute a given executable. exit() terminates a process, and wait() causes a parent to block until a child terminates. Many variants of the above system calls exist with different arguments.
What happens during a fork?
A new process is created by making a copy of the parent’s memory image. This means the child’s code is exactly the same as the parent’s code. The new process is added to the OS process list and scheduled. Parent and child start execution just after the fork statement (with different return values).
Note that parent and child execute and modify the memory data independently (the memory images being a copy of one another does not propagate).
The return values for fork() are set as follows:
-
0for the child process -
< 0ifforkfailed -
PID of the childin the parent
Terminating child processes
A process can be terminated in the following situations
- The process calls
exit()(exit()is called automatically when the end of main is reached) - OS terminated a misbehaving process
The processes are not immediately deleted from the process list upon termination. They exist as zombies. These are cleared out when a parent calls wait(NULL). A zombie child is then cleaned up or “reaped”.
wait() blocks the parent until the child terminates. There are some non-blocking ways to invoke wait.
What if the parent terminates before its child? init process adopts orphans and reaps them. Dark, right? If the init process does not do this, zombies will eat up the system memory. Why do we need zombies? (Too many brains in the world). There are subtle reasons for this, which are out of scope for this discussion.
What happens during exec?
After forking, the parent and the child are running the same code. This is not useful! A process can run exec() to load another executable to its memory image. This allows a child to run a different program from the parent. There are variants of exec(), e.g., execvp(), to pass command-line arguments to the new executable.
Case study: How does a shell work?
In a basic OS, the init process is created after the initialization of hardware. The init spawns a lot of new processes like bash. bash is a shell. A shell reads user commands, forks a child, execs the command executable, waits for it to finish, and reads the next command.
Standard commands like ls are all executables that are simply exec‘ed by the shell.
More funky things about the shell
A shell can manipulate the child in strange ways. For example, you can redirect the output from a command to a file.
prompt > ls > foo.txt
This is done via spawning a child, rewires its standard output to a file, and then calls the executable.
close(STDOUT_FILENO);
open("./p4.output", O_CREAT|O_WRONLY|O_TRUNC, S_IRWXU);
We can similarly modify the input for a process.
Lecture 23 - System calls for process management in xv6
Process system calls: Shell
When xv6 boots up, it starts the init process (the first user process). Init forks shell, which prompts for input. This shell process is the main screen that we see when we run xv6.
Whenever we run a command in the shell, the shell creates a new child process, executes it, waits for the child to terminate, and repeats the whole process again. Some commands have to be executed by the parent process itself and not by the child. For example, cd command should change the parent’s (shell) current directory, not of the child. Such commands are directly executed by the shell itself without forking a new process.
What happens on a system call?
All the system calls available to the users are defined in the user library header ‘user.h’. This is equivalent to a C library header (xv6 doesn’t use a standard C library). System call implementation invokes a special trap instruction called int in x86. All the system calls are defined in “usys.S”.
The trap (int) instruction causes a jump to kernel code that handles the system call. Every system call is associated with a number which is moved into eax to let the kernel run the applicable code. We’ll learn more about this later, so don’t worry about this now.
Fork system call
Parent allocates new process in ptable, copies parent state to the child. The child process set is set to runnable, and the scheduler runs it at a later time. Here is the implementation of fork()
int
fork(void)
{
int i, pid;
struct proc *np;
struct proc *curproc = myproc();
// Allocate process.
if((np = allocproc()) == 0){
return −1;
}
// Copy process state from proc.
if((np−>pgdir = copyuvm(curproc−>pgdir, curproc−>sz)) == 0){
kfree(np−>kstack);
np−>kstack = 0;
np−>state = UNUSED;
return −1;
}
np−>sz = curproc−>sz;
np−>parent = curproc;
*np−>tf = *curproc−>tf;
// Clear %eax so that fork returns 0 in the child.
np−>tf−>eax = 0;
for(i = 0; i < NOFILE; i++)
if(curproc−>ofile[i])
np−>ofile[i] = filedup(curproc−>ofile[i]);
np−>cwd = idup(curproc−>cwd);
safestrcpy(np−>name, curproc−>name, sizeof(curproc−>name));
// Set new pid
pid = np−>pid;
acquire(&ptable.lock);
// Set Process state to runnable
np−>state = RUNNABLE;
release(&ptable.lock);
// Fork system call returns with child pid in parent
return pid;
}
Exec system call
The source code is a little bit complicated. The key steps include
- Copy new executable into memory, replacing the existing memory image
- Create new stack, heap
- Switch process page table to use the new memory image
- Process begins to run new code after system call ends
Exit system call
Exiting a process cleans up the state and passes abandoned children to init. It marks the current process as a zombie and invokes the scheduler.
void
exit(void)
{
struct proc *curproc = myproc();
struct proc *p;
int fd;
if(curproc == initproc)
panic("init exiting");
// Close all open files.
for(fd = 0; fd < NOFILE; fd++){
if(curproc−>ofile[fd]){
fileclose(curproc−>ofile[fd]);
curproc−>ofile[fd] = 0;
}
}
begin_op();
iput(curproc−>cwd);
end_op();
curproc−>cwd = 0;
acquire(&ptable.lock);
// Parent might be sleeping in wait().
wakeup1(curproc−>parent);
// Pass abandoned children to init.
for(p = ptable.proc; p < &ptable.proc[NPROC]; p++){
if(p−>parent == curproc){
p−>parent = initproc;
if(p−>state == ZOMBIE)
wakeup1(initproc);
}
}
// Jump into the scheduler, never to return.
curproc−>state = ZOMBIE;
// Invoke the scheduler
sched();
panic("zombie exit");
}
Remember, the complete cleanup happens only when a parent reaps the child.
Wait system call
It must be called to clean up the child processes. It searches for dead children in the process table. If found, it cleans up the memory and returns the PID of the dead child. Otherwise, it sleeps until one dies.
int
wait(void)
{
struct proc *p;
int havekids, pid;
struct proc *curproc = myproc();
acquire(&ptable.lock);
for(;;){
// Scan through table looking for exited children.
havekids = 0;
for(p = ptable.proc; p < &ptable.proc[NPROC]; p++){
if(p−>parent != curproc)
continue;
havekids = 1;
if(p−>state == ZOMBIE){
// Found one.
pid = p−>pid;
kfree(p−>kstack);
p−>kstack = 0;
freevm(p−>pgdir);
p−>pid = 0;
p−>parent = 0;
p−>name[0] = 0;
p−>killed = 0;
p−>state = UNUSED;
release(&ptable.lock);
return pid;
}
}
// No point waiting if we don’t have any children.
if(!havekids || curproc−>killed){
release(&ptable.lock);
return −1;
}
// Wait for children to exit. (See wakeup1 call in proc_exit.)
sleep(curproc, &ptable.lock);
}
}
Summary of process management system calls in xv6
- Fork - process marks new child’s
struct procasRUNNABLE, initializes child memory image and other states that are needed to run when scheduled - Exec - process reinitializes memory image of user, data, stack, heap, and returns to run new code.
- Exit - process marks itself as
ZOMBIE, cleans up some of its state, and invokes the scheduler - Wait - parent finds any
ZOMBIEchild and cleans up all its state. IF no dead child is found, it sleeps (marks itself asSLEEPINGand invokes scheduler).
When do we call wait in the parent process?
Lecture 4 - Mechanism of process execution
In this lecture, we will learn how an OS runs a process. How it handles system calls, and how it context switches from one process to the other. We are going to understand the low-level mechanisms of these.
Process Execution
The first thing the OS does is, it allocates memory and create a memory image. It also sets up the program counter and other registers. After the setup, the OS is out of the way, and the process executes directly on the CPU by itself.
A simple function call
A function call translates to a jump instruction. A new stack frame is pushed onto the stack, and the stack pointer (SP) is updated. The old value of the PC (return value) is pushed to the stack, and the PC is updated. The stack frame contains return value, function arguments, etc.
How is a system call different?
The CPU hardware has multiple privilege levels. The user mode is used to run the user code. OS code like the system calls run in the kernel mode. Some instructions execute only in kernel mode.
The kernel does not trust the user stack. It uses a separate kernel stack when in kernel mode. The kernel also does not trust the user-provided addresses. It sets up an Interrupt Descriptor Table (IDT) at boot time. The IDT has addresses of kernel functions to run for system calls and other events.
Mechanism of a system call: trap instruction
A special trap instruction is run when a system call must be made (usually hidden from the user by libc). The trap instruction initially moves the CPU to a high privilege level. The stack pointer is updated to switch to the kernel stack. Here, the context, such as old PC, registers, etc., is saved. Then, the address of the system call is looked up in the IDT, and the PC jumps to the trap handler function in the OS code.
The trap instruction is executed on the hardware in the following cases -
- System call - Program needs OS service
- Program faults - Program does something illegal, e.g., access memory that it doesn’t have access to
- Interrupt events - External device needs the attention of OS, e.g., a network packet has arrived on the network card.
In all of the cases, the mechanism is the same as described above. The IDT has many entries. The system calls/interrupts store a number in a CPU register before calling trap to identify which IDT entry to use.
When the OS is done handling the syscall or interrupt, it calls a special instruction called return-from-trap. It undoes all the actions done by the trap instruction. It restores the context of CPU registers from the kernel stack. It changes the CPU privilege from kernel mode to user mode, and it restores the PC and jumps to user code after the trap call.
The user process is unaware that it was suspended, and it resumes execution as usual.
Before returning to the user mode, the OS checks if it has to switch back to the same process or another process. Why do we want to do this? Sometimes when the OS is in kernel mode, it cannot return back to the same process it left. For example, when the original process has exited, it must be terminated (e.g., due to a segfault) or when the process has made a blocking system call. Sometimes, the OS does not want to return back to the same process. Maybe the process has run for a long time, Due to the timesharing responsibility, the OS switches to another process. In such cases, OS is said to perform a context switch to switch from one process to another.
OS scheduler
The OS scheduler is responsible for the context switching mechanism. It has two parts - A policy to pick which process to run and a mechanism to switch to that process. There are two different types of schedulers.
A non-preemptive (cooperative) scheduler is polite. It switches only when a process is blocked or terminated. On the other hand, a preemptive (non-cooperative) schedulers can switch even when the process is ready to be continued. The CPU generates a periodic timer interrupt to check if a process has run for too long. After servicing an interrupt, a preemptive scheduler switches to another process.
Mechanism of context switch
Suppose a process A has moved from the user to kernel mode, and the OS decides it must switch from A to B. Now, the OS’s first job is saving the context (PC, registers, kernel stack pointer) of A on the kernel stack. Then, the kernel stack pointer is switched to B, and B’s context is restored from B’s kernel stack. This context was saved by the OS when it switched out of B in the past. Now, the CPU is running B in kernel mode, return-from-trap to switch to user mode of B.
A subtlety on saving context
The context (PC and other registers) of a process is saved on the kernel stack in two different scenarios.
When the OS goes from user mode to kernel mode, user context (e.g., which instruction of user code you stopped at) is saved on the kernel stack by the trap instruction. This is later restored using the return-from-trap instruction. The other scenario where you store the context is during a context switch. The kernel context (e.g., where you stopped in the OS code) of process A is saved on the kernel stack of A by the context-switching code, and B’s context is restored.
Live Session 2
-
As the shell user, you don’t have to call
fork,exec,waitandexit. The shell automatically takes care of this. -
The stack pointer’s current location is stored in a general-purpose register before jumping from the user stack to the kernel stack.
-
Why don’t we create an empty system image for a child process? Some instructions (in Windows) require the child to run the parent’s code. We can’t initialize an empty image. There are some advantages to copying the memory image of the parent into the child. The modern OSs utilize copy on demand.
When a child is created, the PC points to the instruction after
fork(). This prevents the OS from callingfork()recursively.fork()can return \(-1\) instead of the child’s PID if the process creation fails. -
wait()reaps only a single child process. We need to call it again if we need to reap more children. With some variants ofwait(), we can delete a specific child.wait()is designed this way so that the parent knows which child has been reaped. This information is important for later instructions. Returning an array of variable size is not a feasible option.
Lecture 24 - Trap Handling
What is a trap? In certain scenarios, the user programs have to trap into the OS/kernel code. The following events cause a user process to “trap” into the kernel (xv6 refers to these events as traps)
- System calls - requests by user for OS services
- Interrupts - External device wants attention
- Program fault - Illegal action by a program
When any of the above events happen, the CPU executes the special int instruction. The user program is blocked. A trap instruction has a parameter int n, indicating the type of interrupt. For example, syscall has a different value for \(n\) from a keyboard interrupt.
Before the trap instruction is executed, eip points to the user program instruction, and esp to user stack. When an interrupt occurs, the CPU executes the following step s as part of the int n instruction -
- Fetch the \(n\)th entry interrupt descriptor table (CPU knows the memory address of IDT)
- Save stack pointer (
esp) to an internal register - Switch
espto the kernel stack of the process (CPU knows the location of the kernel stack of the current process - task state segment) - On the kernel stack, save the old
esp,eip, etc. - Load the new
eipfrom the IDT, which points to the kernel trap handler.
Now, the OS is ready to run the kernel trap handler code on the process’s kernel stack. Few details have been omitted above -
- Stack, code segments (
cs,ss), and a few other registers are also saved. - Permission check of CPU privilege levels in IDT entries. For example, a user code can invoke the IDT entry of a system call but not of a disk interrupt.
- Suppose an interrupt occurs when the CPU is already handling a previous interrupt. In that case, we don’t have to save the stack pointer again.
Why a separate trap instruction?
Why can’t we simply jump to kernel code, like we jump to the code of a function in a function call? The reasons are as follows -
- The CPU is executing the user code at a lower privilege level, but the OS code must run at a higher privilege.
- The user program cannot be trusted to invoke kernel code on its own correctly.
- Someone needs to change the CPU privilege level and give control to the kernel code.
- Someone also needs to switch to the secure kernel stack so that the kernel can start saving the state.
Trap frame on the kernel stack
Trap frame refers to the state pushed on the kernel stack during trap handling. This state includes the CPU context of where execution stopped and some extra information needed by the trap handler. The int n instruction pushes only the bottom few entries of the trap frame. The kernel code pushes the rest.
Kernel trap handler (alltraps)
The IDT entries for all interrupts will set eip to point to the kernel trap handler alltraps. The alltraps assembly code pushes the remaining registers to complete the trap frame on the kernel stack. pushal pushes all the general-purpose registers. It also invokes the C trap handling function named trap. The top of the trap frame (current top of the stack - esp) is given as an argument to the C function.
The convention of calling C functions is to push the arguments on to the stack and then call the function.
C trap handler function
The C trap handler performs different actions based on the kind of trap. For example, say we have to execute a system call. The function invokes int n. The system call number is taken from the register eax (whether fork, exec, etc.). The return value of the syscall is stored in eax after execution.
Suppose we have an interrupt from a device; the corresponding device-related code is called. The trap number is different for different devices. A timer interrupt is a special hardware interrupt, and it is generated periodically to trap to the kernel. On a timer interrupt, a process yields CPU to the scheduler. This interrupt ensures a process does not run for too long.
Return from trap
The values from the kernel stack have to be popped. The return from trap instruction iret does the opposite of int. It pops the values and changes the privilege level back to a lower level. Then, the execution of the pre-trap code can resume.
Summary of xv6 trap handling
- System calls, program faults, or hardware interrupts cause the CPU to run
int ninstruction and “trap” to the OS. - The trap instruction causes the CPU to switch
espto the kernel stack,eipto the kernel trap handling code. - The pre-trap CPU state is saved on the kernel stack in the trap frame. This is done both by the
intinstruction and thealltrapscode. - The kernel trap handler handles the trap and returns to the pre-trap process.
Lecture 25 - Context Switching
Before we understand context switching, we need to understand the concepts related to processes and schedulers in xv6. In xv6, every CPU has a attribute called a scheduler thread. It is a special process that runs the scheduler code. The scheduler goes over the list of processes and switches to one of the runnable processes. after running for sometime, the process switches back to the scheduler thread. This can happen in the following 3 ways -
- Process has terminated
- Process needs to sleep
- Process yields after running for a long time
A context switch only happens when the process is already in the kernel mode.
Scheduler and sched
The scheduler switches to a user process in the scheduler function. User processes switch to the scheduler thread in the sched function (invoked from exit, sleep, yield).
void
scheduler(void)
{
struct proc *p;
struct cpu *c = mycpu();
c−>proc = 0;
for(;;){
// Enable interrupts on this processor.
sti();
// Loop over process table looking for process to run.
acquire(&ptable.lock);
for(p = ptable.proc; p < &ptable.proc[NPROC]; p++){
if(p−>state != RUNNABLE)
continue;
// Switch to chosen process. It is the process’s job
// to release ptable.lock and then reacquire it
// before jumping back to us.
c−>proc = p;
switchuvm(p);
p−>state = RUNNING;
swtch(&(c−>scheduler), p−>context);
switchkvm();
// Process is done running for now.
// It should have changed its p−>state before coming back.
c−>proc = 0;
}
release(&ptable.lock);
}
}
The sched function is as follows
void
sched(void)
{
int intena;
struct proc *p = myproc();
if(!holding(&ptable.lock))
panic("sched ptable.lock");
if(mycpu()−>ncli != 1)
panic("sched locks");
if(p−>state == RUNNING)
panic("sched running");
if(readeflags()&FL_IF)
panic("sched interruptible");
intena = mycpu()−>intena;
swtch(&p−>context, mycpu()−>scheduler);
mycpu()−>intena = intena;
}
The high level view is

When does a process call sched?
Yield - A timer interrupt occurs when a process has run for a long enough time.
Exit - The process has exit and set itself as zombie.
Sleep - A process has performed a blocking action and set itself to sleep.
struct context
This structure is saved and restored during a context switch. It is basically a set of registers to be saved when switching from one process to another. For example, we must save eip which signifies where the process has stopped. The context is pushed onto the kernel stack and the struct proc maintains a pointer to the context structure on the stack.
Now, the obvious question is “what is the difference between this and the trap frame?” We shall look into it now.
Context structure vs. Trap frame
The trapframe (p -> tf) is saved when the CPU switches to the kernel mode. For example, eip in the trapframe is the eip value where the syscall was made in the user code. On the other hand, the context structure is saved when process switches to another process. For example, eip value when swtch is called. Both these structures reside on the kernel stack and struct proc has pointers to both of them. Although, they differ in the content they store. This sort of clears up the confusion in the subtlety of memory storage in the kernel stack.
swtch function
This function is invoked both by the CPU thread and the process. It takes two arguments, the address of the pointer of the old context and the pointer of the new context. We are not sending the address of the new context, but the context pointer itself.
// When invoked from the scheduler: address of scheduler's context pointer, process context pointer
swtch(&(c -> scheduler), p -> context);
// When invoked from sched: address of process context pointer, scheduler context pointer
swtch(&p -> context, mycpu() -> scheduler);
When a process/thread has invoked the swtch, the stack has caller save registers and the return address (eip). swtch does the following -
- Push the remaining (callee save) registers on the old kernel stack.
- Save the pointer to this context into the context structure pointer of the old process.
- Switch
espfrom the old kernel stack to the new kernel stack. -
espnow points to the saved context of new process. This is the primary step of a context switch. - Pop the callee-save registers from the new stack.
- Return from the function call by popping the return address after the callee save registers.
The assembly code of swtch is as follows -
# Context switch
void swtch(struct context **old, struct context *new);
Save the current registers on the stack, creating
a struct context, and save its address in *old.
Switch stacks to new and pop previously−saved registers.
.globl swtch
swtch:
movl 4(%esp), %eax
movl 8(%esp), %edx
# Save old callee−saved registers
pushl %ebp
pushl %ebx
pushl %esi
pushl %edi
# Switch stacks
# opposite order compared to MIPS
# movl src dst
movl %esp, (%eax)
movl %edx, %esp
# Load new callee−saved registers
popl %edi
popl %esi
popl %ebx
popl %ebp
ret
eax has the address of the pointer to the old context and edx has the pointer to the new context.
Why address of pointer?
Summary of context switching in xv6
The old process, say P1, goes into the kernel mode and gives up the CPU. The new process, say P2, is ready to run. P1 switches to the CPU scheduler thread. The scheduler thread finds P2 and switches to it. Then, P2 returns from trap to user mode. The process of switching from one process/thread to another involves the following steps. All the register states (CPU context) on the kernel stack of the old process are saved. The context structure pointer of the old process is updated to this saved context. Then, esp moves from the old kernel stack to the new kernel stack. Finally, the register states are restored in the new kernel stack to resume the new process.
Lecture 26 - User process creation
We know that the init process is created when xv6 boots up. The init process forks a shell process, and the shell is used to spawn any user process. The function allocproc is called during both init process creation and in fork system call.
allocproc
It iterates over the ptable, finds an unused entry, and marks it as an embryo. This entry is later marked as runnable after the process creation completes. It also allocates a new PID for the process. Then, allocproc has to allocate space on the kernel stack. To do this, we start from the bottom of the stack and find some free space. We leave room for the trap frame. Then, we push the return address of trapret and also the context structure with eip pointing to the function forkret. When the new process is scheduled, it begins execution at forkret, returns to trapret, and finally returns from the trap to the user space.
The role of allocproc is to create a template kernel stack, and make the process look like it had a trap and was context switched out in the past. This is done so that the scheduler can switch to this process like any other.
Where is kernel mode? The sp points to the kernel stack.
allocproc(void)
{
struct proc *p;
char *sp;
acquire(&ptable.lock);
for(p = ptable.proc; p < &ptable.proc[NPROC]; p++)
if(p−>state == UNUSED)
goto found;
release(&ptable.lock);
return 0;
found:
p−>state = EMBRYO;
p−>pid = nextpid++;
release(&ptable.lock);
// Allocate kernel stack.
if((p−>kstack = kalloc()) == 0){
p−>state = UNUSED;
return 0;
}
sp = p−>kstack + KSTACKSIZE;
// Leave room for trap frame.
sp −= sizeof *p−>tf;
p−>tf = (struct trapframe*)sp;
// Set up new context to start executing at forkret,
// which returns to trapret.
sp −= 4;
*(uint*)sp = (uint)trapret;
sp −= sizeof *p−>context;
p−>context = (struct context*)sp;
memset(p−>context, 0, sizeof *p−>context);
p−>context−>eip = (uint)forkret;
return p;
}
Init process creation
The userinit function is called to create the init process. This is also done using the allocproc function. The trapframe of init is modified, and the process is set to be runnable. The init program opens STDIN, STDOUT and STDERR files. These are inherited by all subsequent processes as child inherits parent’s files. It then forks a child, execs shell executable in the child, and waits for the child to die. It also reaps dead children.
Forking a new process
Fork allocates a new process via allocproc. The parent memory image and the file descriptors are copied. Take a look at the fork code while you’re reading this. The trapframe of the child is copied from that of the parent. This allows the child execution to resume from the next instruction after fork(). Only the return value in eax is changed so that the child returns its PID. The state of the new child is set to runnable, and the parent returns normally from the trap/system call.
Summary of new process creation
New processes are created by marking a new entry in the ptable as runnable after configuring the kernel stack, memory image etc of the new process. The kernel stack of the new process is made to look like that of a process that had been context switched out in the past.
Live Session 3
-
What is a scheduler thread? It is a kernel process that is a part of the OS. It always runs in kernel mode, and it is not a user -level process.
-
int nis a hardware instruction and is enabled by a hardware descriptor language. It is similar to, say, theaddinstruction. Why is it a hardware instruction? We don’t trust the software. As it is a hardware instruction, we can trust the CPU maker to bake the chip correctly. -
The
trapframehas the user context, and the context structure has the kernel context. Every context switch is preceded by a trap instruction. A context switch only happens in the kernel mode. Now, what if a user process does not go to the kernel mode ever? The timer interrupt will take care of this. It will prompt the process to go into trap mode if the process has run for too long. -
In the subtlety on saving context, the first point refers to storing the trapframe. The second point refers to storing the context structure.
-
forkretis a small function that a program has to execute after a process has been created. This mainly involves the locking mechanism that will be discussed later.forkis a wrapper ofallocproc -
schedis only called by the user processes in case ofsleep,exit, andyield.schedstores the context of the current context onto the kernel stack. Theschedulerfunction is called by the scheduler thread to switch to a new process. Both of these functions call theswtchfunction to switch the current process. Think of the CPU scheduler (scheduler thread) as an intermediate process that has to be executed when switching from process A to process B.Why do we need this intermediate process? Several operating systems make do without a scheduler thread. This is modular, and xv6 chose this methodology. The
schedulerfunction simply uses the Round Robin algorithm.
Lecture 5 - Scheduling Policy
What is a scheduling policy? It is a program that decides which program to run at a given time from the set of ready processes. The OS scheduler schedules the CPU requests (bursts) of processes. CPU burst refers to the CPU time used by a process in a continuous stretch. For example, if a process comes back after an I/O wait, it counts as a fresh CPU burst.
Our goal is to maximize CPU utilization, and minimize the turnaround time of a process. The turnaround time of a process refers to the time between the process’s arrival and its completion. The scheduling policy must also minimize the average response time, from process arrival to the first scheduling. We should also treat all processes fairly and minimize the overhead. The amortized cost of a context switch is high.
We shall discuss a few scheduling policies and their pros/cons below.
First-In-First-Out (FIFO)
Schedule the processes as an when they arrive in the CPU. The drawback of this method is the convoy effect. In this situation, a process takes high time to execute and effectively increases the turnaround time.
Shortest Job First (SJF)
This is provably optimal when all processes arrive together. Although, this is a non-preemptive policy. Short processes can still be stuck behind the long ones when the long process arrives first.
Shortest Time-to-Completion First
This is a preemptive version of SJF. This policy preempts the running task is the remaining time to execute the process is more than that of the new arrival. This method is also called the Shortest Remaining Time First (SRTF).
How do we know the running time/ time left of a process? We schedule processes in bursts! No, that’s wrong! See this

Round Robin (RR)
Every process executes for a fixed quantum slice. The slice is big enough to amortize the cost of a context switch. This policy is also preemptive! It has a good response time and is fair. Although, it may have high turnaround times.
Schedulers in Real systems
Real schedulers are more complex. For example, Linux uses a policy called Multi-Level Feedback Queue (MLFQ). You maintain a set of queues and prioritize them. A process is picked from the highest priority queue. Processes in the same priority level are scheduled using a policy like RR. The priority of a queue decays with its age.
Lecture 6 - Inter-Process Communication (IPC)
In general, two processes do not share any memory with each other. Some processes might want to work together for a task, and they need to communicate information. The OS provides IPC mechanisms for this purpose.
Types of IPC mechanisms
Shared Memory
Two processes can get access to the same region of the memory via shmget() system call.
int shmget(key_t key, int size, int shmflg)
By providing the same key, two processes can get the same segment of memory.
How do they know keys?
Although, when realizing this idea, we need to consider some problematic scenarios. For example, we need to take care that one process is not overwriting another’s data.
Signals
These are well-defined messages that can be sent to processes that are supported by the OS. Some signals have a fixed meaning. For example, a signal to terminate a process. Some signals can also be user-defined. A signal can be sent to a process by the OS or another process. For example, when you type Ctrl + C, the OS sends SIGINT signal to the running process.
These signals are handled by a signal handler. Every process has a default code to execute for each signal. Some (Can’t edit the terminate signal) of these signal handlers can be overridden to do other things. Although, you cannot send messages/bytes in this method.
Sockets
Sockets can be used for two processes on the same machine or different machines to communicate. For example, TCP/UDP sockets across machines and Unix sockets in a local machine. Processes open sockets and connect them to each other. Messages written into one socket can be read from another. The OS transfers the data across socket buffers.
Pipes
These are similar to sockets but are half-duplex - information can travel only in one direction. A pipe system call returns two file descriptors. These are simply handles that can read and write into files (read handle and write handle). The data written in one file descriptors can be read through another.
In regular pipes, both file descriptors are in the same process. How is this useful? When a parent forks a child process, the child process has access to the same pipe. Now, the parent can use one end of the pipe, and the child can use the other end.
Named pipes can be used to provide two endpoints a pipe to different processes. The pipe data is buffered in OS (kernel) buffers between write and read.
Message Queues
This is an abstraction of a mailbox. A process can open a mailbox at a specified location and send/receive messages from the mailbox. The OS buffers messages between send and receive.
Blocking vs. non-blocking communication
Some IPC actions can block
- reading from a socket/pip that has no data, or reading from an empty message queue
- Writing to a full socket/pip/message queue
The system calls to read/write have versions that block or can return with an error code in case of a failure.
Lecture 7 - Introduction to Virtual memory
The OS provides a virtualized view of the memory to a user process. Why do we need to do this? Because the real view of memory is messy! In the olden days, the memory had only the code of one running process and the OS code. However, the contemporary memory structure consists of multiple active processes that timeshare the CPU. The memory of a single process need not be contiguous.
The OS hides these messy details of the memory and provides a clean abstraction to the user.
The Abstraction: (Virtual) Address Space
Every process assumes it has access to a large space of memory from address - to a MAX value. The memory of a process, as we’ve seen earlier, has code (and static data), heap (dynamic allocations), and stack (function calls). Stack and heap of the program grow during runtime. The CPU issues “loads” and “stores” to these virtual addresses. For example, when you print the address of a variable in a program, you get the virtual addresses!
Translation of addresses
The OS performs the address translation from virtual addresses (VA) to physical addresses (PA) via a memory hardware called Memory Management Unit (MMU). The OS provides the necessary information to this unit. The CPU loads/stores to VA, but the memory hardware accesses PA.
Example: Paging
This is a technique used in all modern OS. The OS divides the virtual address space into fixed-size pages, and similarly, the physical memory is segmented into frames. To allocate memory, a page is mapped to a free physical frame. The page table stores the mappings from the virtual page number to the physical frame number for a process. The MMU has access to these page tables and uses them to translate VA to PA.
Goals of memory virtualization
- Transparency - The user programs should not be aware of the actual physical addresses.
- Efficiency - Minimize the overhead and wastage in terms of memory space and access time.
- Isolation and Protection - A user process should not be able to access anything outside its address space.
How can a user allocate memory?
The OS allocates a set of pages to the memory image of the process. Within this image
- Static/global variables are allocated in the executable.
- Local variables of a function are allocated during runtime on the stack.
- Dynamic allocation with
mallocon the heap.
Memory allocation is done via system calls under the hood. For example, malloc is implemented by a C library that has algorithms for efficient memory allocation and free space management.
When the program runs out of the initially allocated space, it grows the heap using the brk/sbrk system call. Unlike fork, exec, and wait, the programmer is discouraged from using these system calls directly in the user code.
A program can also allocate a page-sized memory using the mmap() system call and get an anonymous (empty, will be discussed later) page from the OS.
A subtlety in the address space of the OS
Where is the OS code run? OS is not a separate process with its own address space. Instead, the OS code is a part of the address space of every process. A process sees OS as a part of its code! In the background, the OS provides this abstraction. However, in reality, the page tables map the OS addresses to the OS code.
Also, the OS needs memory for its data structures. How does it allocate memory for itself? For large allocation, the OS allocates itself a page. For smaller allocations, the OS uses various memory allocation algorithms (will be discussed later). Note. The OS cannot use libc and malloc in the kernel.
Why?
Live Session 4
- The scheduler/PC does not always know the running time of the processes. Therefore, we can’t implement SJF and SRTF in practice.
- The shared key is shared offline (say, via a command-line argument) in the shared memory IPC.
- Every process has a set of virtual addresses that it can use.
mmap()is used to fetch the free virtual addresses. It is mainly used for allocating large chunks of memory (allocates pages). It can be used to get general memory and not specifically for heap. On the other hand,brkandsbrkgrow the heap in small chunks.mallocuses these two system calls for expanding memory. - Conceptually, sockets and message queues are the same. The two structures just have a different programming interface.
-
libcandmalloccan’t be used in the kernel because these are user-space libraries. The kernel has its own versions of these functions. Variants. - The C library grows the heap. The OS grows the stack. This is because the heap memory is an abstraction provided by the C libraries. The C library gets a page of memory using
mmap()and provides a small chunk of this page to the user whenmalloc()is called. Suppose the stack runs out of the allocated memory. In that case, the OS either allocates new memory and transfers all the content if required or terminates the process for using a lot of memory.
Lecture 8 - Mechanism of Address Translation
Suppose we have written a C program that initializes a variable and adds a constant to it. This code is converted into an assembly code, each instruction having an address. The virtual address space is set up by the OS during process creation.
Can we use heap from an assembly code?
The OS places the memory images in various chunks (need not be contiguous). However, we shall be considering a simplified version of an OS where the entire memory image is placed in a single chunk. We need the OS to access the physical memory given the virtual address. Also, the OS must detect an error if a program tries to access the memory that is outside the bounds.
Who performs address translation?
In this simple example, the OS can tell the hardware the base and the bound/size values. The MMU calculates PA from VA. The OS is not involved in every translation!
Basically, the CPU provides a privileged mode of execution. The instruction set has privileged instructions to set translation information (e.g., base, bound). We don’t want the user programs to be able to set this information. Then, the MMU uses this information to perform translation on every memory access. The MMU also generates faults and traps to OS when an access is illegal.
Role of OS
What does the OS do? The OS maintains a free list of memory. It allocates spaces to process during creation and cleans up when done. The OS also maintains information of where space is allocated to each process in PCBs. This information is provided to the hardware for translation. Also, the information has to be updated on context switch in the MMU. Finally, the OS handles traps due to illegal memory access.
Segmentation
The base and bound method is a very simple method to store the memory image. Segmentation is a generalized method to store each segment of the memory image separately. For example, the base/bound values of the heap, stack, etc., are stored in the MMU. However, segmentation is not popularly used. Instead, paging is used widely.
Segmentation is suitable for sparse address spaces.
Stack and heap grow in the physical address space?
Although, segmentation uses variable-sized allocation, which leads to external fragmentation - small holes in the memory left unused.
Lecture 9 - Paging
The memory image of a process is split into fixed-size chunks called pages. Each of these pages is mapped to a physical frame in the memory. This method avoids external fragmentation. Although, there might be internal fragmentation. This is because sometimes the process requires much less memory than the size of a page, but the OS allocates memory in fixed-size pages. However, internal fragmentation is a small problem.
Page Table
This is a data structure specific to a process that helps in VA-PA translation. This structure might be as simple as an array storing mappings from virtual page numbers (VPN) to physical frame numbers (PFN). This structure is stored as a part of the OS memory in PCB. The MMU has access to the page tables and uses them for address translation. The OS has to update the page table given to the MMU upon a context switch.
Page Table Entry (PTE)
The most straightforward page table is a linear page table, as discussed above. Each PTE contains PFN and a few other bits
- Valid bit - Is this page used by the process?
- Protection bits - Read/write permissions
- Present bit - Is this page in memory? (will be discussed later)
- Dirty bit - Has this page been modified?
- Accessed bit - Has this page been recently accessed?
Address translation in hardware
A virtual address can be separated into VPN and offset. The most significant bits of the VA are the VPN. The page table maps VPN to PFN. Then, PA is obtained from PFN and offset within a page. The MMU stores the (physical) address of the start of the page table, not all the entries. The MMU has to walk to the relevant PTE in the page table.
Suppose the CPU requests code/data at a virtual address. Now, the MMU has to access the physical memory to fetch code/data. As you can see, paging adds overhead to memory access. We can reduce this overhead by using a cache for VA-PA mappings. This way, we need not go to the page table for every instruction.
Translation Lookaside Buffer (TLB)
Ignore the name. Basically, it’s a cache of recent VA-PA mappings. To translate VA to PA, the MMU first looks up the TLB. If the TLB misses, the MMU has to walk the page table. TLB misses are expensive (in the case of multiple memory accesses). Therefore, a locality of reference helps to have a high hit rate. For example, a program may try to fetch the same data repeatedly in a loop.
Note. TLB entries become invalid on context switch and change of page tables.
Page table can change without context switch?
Also, this cache is not taken care of by the OS but by the architecture itself.
How are page tables stored in the memory?
A typical page table has 2^20 entries in a 32-bit architecture (32 bit VA) and 4KB pages
2^32 (4GB RAM)/ 2^12 (4KB pages)
If each PTE is 4 bytes, then page table is 4MB! How do we reduce the size of page tables? We can use large pages. Still, it’s a tradeoff.
How does the OS allocate memory for such large tables? The page table is itself split into smaller chunks! This is a multilevel page table.
Multilevel page tables
A page table is spread over many pages. An “outer” page table or page directory tracks the PFNs of the page table pages. If a page directory can’t fit in a single page, we may use more than 2 levels. For example, 64-bit architectures use up to 7 levels!
How is the address translation done in this case? The first few bits of the VA identify the outer page table entry. The next few bits are used to index into the next level of PTEs.
What about TLB misses? We need to perform multiple access to memory required to access all the levels of page tables. This is a lot of overhead!
Lecture 10 - Demand Paging
The main memory may not be enough to store all the page tables of active processes. In such cases, the OS uses a part of the disk (swap space) to store pages that are not in active use. Therefore, physical memory is allocated on demand, and this is called demand paging.
Page Fault
The present bit in the page table entry indicates if a page of a process resides in the main memory or not (swap). When translating from VA to PA, the MMU reads the present bit. If the page is present in the memory, the location is directly accessed. Otherwise, the MMU raises a trap to the OS - page fault. (No fault happened, actually).
The page fault traps OS and moves CPU to kernel mode like any other system call. Then, the OS fetches the disk address of the page and issues a “read” to the disk. How does the OS know the location of pages on the disk? It keeps track of disk addresses (say, in a page table). The OS context switches to another process, and the current process is blocked.
Suppose the CPU context switches from the MMU read from swap to another process. When it comes back to the process, the disk would have fetched the address from the swap. How does the MMU revert back to its previous state? The other process to which the CPU context switched will have used the MMU. -> See the below paragraph
Eventually, when the disk read completes, the OS updates the process’s page table and marks the process as ready. When the process is scheduled again, the OS restarts the instruction that caused the page fault.
Summary - Memory Access
The CPU issues a load to a VA for code/data. Before sending a request, the CPU checks its cache first. It goes to the main memory if the cache misses. Note. This is not the TLB cache.
After the control reaches the main memory, the MMU looks up the TLB for VA. If TLB is hit, the PA is obtained, and the code/data is returned to the CPU. Otherwise, the MMU accesses memory, walks the page table (maybe multiple levels), and obtains the entry.
- If the present bit is set in PTE, the memory is accessed. Think about this point carefully. The frame may be present in physical memory or the swap.
- The MMU raises a page fault if the present bit is not set but is valid access. The OS handles page fault and restarts the CPU load instruction
- In the case of invalid page access, trap to OS for illegal access.
Complications in page faults
What does the OS do when servicing a page fault if there is no free page to swap in the faulting page? The OS must swap out an existing page (if modified, i.e., dirty) and then swap in the faulting page. However, this is too much work! To avoid this, the OS may proactively swap out pages to keep the list of free pages. Pages are swapped out based on the page replacement policy.
Page Replacement policies
The optimal strategy would be to replace a page that is not needed for the longest time in the future. This is not practical. We can use the following policies -
FIFO Policy - Replace the page that was brought into the memory the earliest. However, this may be a popular page.
LRU/LFU - This is commonly used in practical OS. In this policy, we replace the page that was least recently (or frequently) used in the past.
Example - Page Replacement Policy
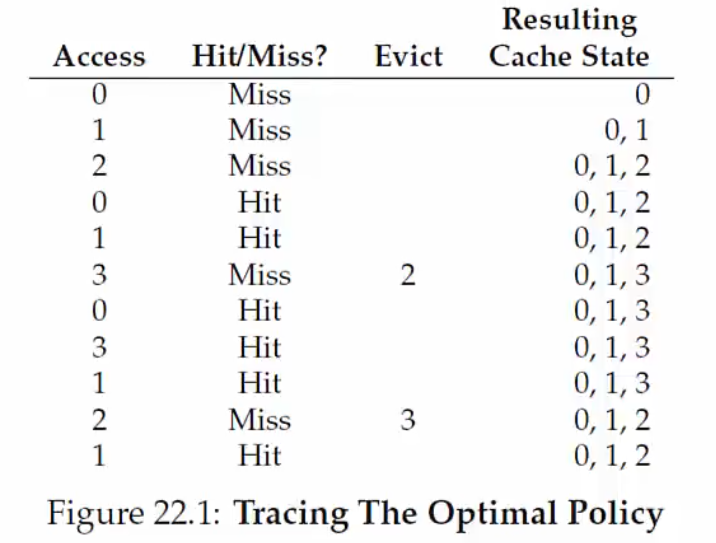
Suppose we can store only 3 frames in the physical memory, and there are 4 pages in the process. The set of accesses is also known as the reference string. Note that the initial few accesses are definitely missed, as the cache is empty - cold misses. The goal is to reduce the number of page faults, which leads to reading from the swap space and is slow.
Belady’s anomaly - The performance of the FIFO may get worse when the memory size increases.
The LRU works better as it makes use of the locality of references.
How is LRU implemented?
The OS is not involved in every memory access.
Why?
Therefore, the OS does not know which page is the LRU. There is some hardware help and some approximations which help the OS to find the LRU page. The MMU sets a bit in the PTE (accessed bit) when a page is accessed. The OS periodically looks at this bit to estimate pages that are active and inactive.
How often does the OS check this? Going through all pages also takes time. Are interrupts used?
The OS tries to find a page that does not have the access bit set to replace a page. It can also look for a page with the dirty bit not set to avoid swapping out to disk.
If the dirty bit is set, using that page would involve writing to disk. Why?
Lecture 11 - Memory Allocation Algorithms
Let us first discuss the problems with variable/dynamic size allocation. This is done from the C library - allocates one or more pages from the kernel via brk/sbrk mmap system calls. The user may ask for variable-sized chunks of memory and can arbitrarily free the used memory. The C library and the kernel (for its internal data structures) must take care of all this.
Variable sized allocation - Headers
Consider a simple implementation of malloc. An available chunk of memory is allocated on request. Every assigned piece has a header with info like chunk size, checksum/some magic number, etc. Why store size? We should know how much memory to free when free is called.
Free List
How is the free space managed? It is usually handled as a list. The library keeps track of the head of the list. The pointer to the next free chunk is embedded within the current head. Allocations happen from the head.
External Fragmentation
Suppose 3 allocations of size 100 bytes each happen. Then, the middle chunk pointed to by sptr is freed. How is the free list updated? It now has two non-contiguous elements. The free space may be scattered around due to fragmentation. Therefore, we cannot satisfy a request for 3800 bytes even though we have free space. This is the primary problem of variable allocation.
Note. The list is updated to account for the newly freed space. That is, the head is revised to point to sptr, and the list is updated accordingly. Don’t be under the false impression that we are missing out on free space.
Splitting and Coalescing
Suppose we have a bunch of adjacent free chunks. These chunks may not be adjacent in the list. If we had started out with a big free piece, we might end up with small tangled chunks. We need an algorithm that merged all the contiguous free fragments into a bigger free chunk. We must also be able to split the existing free pieces to satisfy the variable requests.
Buddy allocation for easy coalescing
Allocate memory only in sizes of power of 2. This way, 2 adjacent power-of-2 chunks can be merged to form a bigger power-of-2 chunk. That is, buddies can be combined to form bigger pieces.
Variable Size Allocation Strategies
First Fit - Allocate the first chunk that is sufficient
Best Fit - Allocate the free chunk that is closest in size to the request.
Worst Fit - Allocate the free chunk that is farthest in size. Sounds odd? It’s better sometimes as the remaining free space in the chunk is large and is more usable. For example, the best fit might allocate a 20-byte chunk for a malloc(15), and the worst might give a 100-byte chunk for the same call. Now, the 85-byte free space is more usable than the 5-byte free space.
Do we use this in the case of buddy allocation?
Fixed Size allocations
Fixed-size allocations are much simpler as they avoid fragmentation and various other problems. The kernel issues fix page-sized allocations. It maintains a free list of pages, and the pointer to the following free page is stored in the current free page itself. What about smaller allocations (e.g., PCB)? The kernel uses a slab allocator. It maintains object caches for each type of object. Within each cache, only fixed size allocation is done. Each cache is made up of one or more slabs. Within a page, we have fixed size allocations again.
Fixed size memory allocators can be used in user programs too. malloc is a generic memory allocator, but we can use other methods too.
Live Session 5
-
Dirty bit -The MMU sets this bit (unlike the present bit and valid bit, which are set by the OS) when the page is recently swapped into the memory. The OS needs this while evicting pages from the memory.
Basically, when you swap in a page frame from the disk to the main memory, you copy-paste the frame. When the page in the main memory is modified, it is not in sync with the page in the disk. At this point, the MMU sets the dirty bit.
-
A page can be in
- Swap
- Main Memory
- Unallocated
Now, note that all of the 4GB memory space need not be allocated.
When the address is not allocated at all, the valid bit is unset. Whenever a virtual address is accessed, and consequently, the memory is allocated (allocated in the main memory), the valid bit is set. This memory allocation is triggered by a page fault. Initially, the newly allocated memory has the present bit set (since we just allocated the memory, we will use it). A page is swapped into the disk when not in active use, and the present bit is unset.
-
Access bit is set whenever a page is accessed. The bit is unset periodically by the OS.
-
The device driver maintains a queue to process multiple reads/writes to the disk.
-
The OS code is mapped into the virtual address space of the processes. It has all the OS information, PCBs, etc. This way, there wouldn’t be much hassle during context switching. The page table of a process also has entries for the OS code.
The OS memory inside the process memory can increase. If it takes too much space, the modern OS has some techniques to prevent the OS space from encroaching the process’s memory space.
A PTE also has permission bits that prevent the user code from accessing the OS code. When the program has to access the OS code, the trap instruction switches us into a higher privilege level and moves us into the OS code.
After we enter the kernel mode, we still cannot modify the OS code in any way we want. This is because we enter the kernel mode using thoroughly defined system calls.
Remember, the
int ninstruction is run by the hardware. -
Every time the page table is updated, the TLB has to be updated too. This is done via special instructions.
-
The user code runs natively on the CPU. The OS asks the CPU to execute the instructions sequentially. Then, the OS is out of the picture. All the memory fetches are done via the CPU.
Now, you may think, when does the OS actually be involved in the memory access. The OS has to periodically check over the processes (maybe during access bit updates). Even when system calls are made, the OS has a play.
-
There is a hardware register where the address of the page table is stored. The MMU accesses the page table using this address.
Lecture 27 - Virtual Memory and paging in xv6
We have a 32-bits version on xv6; thereby, we have \(2^{32} =\) 4GB virtual address space for every process. The process address space is divided into pages (4KB by default). Every valid logical page used by the process is mapped to a physical frame by the OS (no demand paging). There is a single page table entry per page containing the physical frame number (PFN) and various flags/permissions for the page.
Page table in xv6
There can be up to \(2^{20}\) page table entries for a process with the properties we have described above. Each PTE has a 20-bit physical frame number and some flags
-
PTE_Pindicates if a page is present. If not set, access will cause a page fault. -
PTE_Windicates if writable. If not set, only reading is permitted -
PTE_Uindicates if user page. If not set, only the kernel can access the page.
Address translation is done via the page number (top 20 bits of a virtual address) to index into the page table, find the PFN, add a 12-bit offset (for navigating inside the frame).
Two-level page table
All the \(2^{20}\) entries can’t be stored contiguously. Therefore, the page table in xv6 has two levels. We have \(2^{10}\) inner page tables pages, each with \(2^{10}\) PTEs. The outer page director stores PTE-like references to the \(2^{10}\) inner page tables. The physical address of the outer page directory is stored in the CPU’s cr3 register, which is used by the MMU during address translation.
A virtual address ’la’ has a three−part structure as follows:
+−−−−−−−−10−−−−−−+−−−−−−−10−−−−−−−+−−−−−−−−−12−−−−−−−−−−+
| Page Directory | Page Table | Offset within Page |
| Index | Index | |
+−−−−−−−−−−−−−−−−+−−−−−−−−−−−−−−−−+−−−−−−−−−−−−−−−−−−−−−+
\−−− PDX(va) −−/ \−−− PTX(va) −−/
Therefore, we now have 32-bit virtual addresses.
Process virtual address space in xv6
The memory image of a process starting at address 0 has the following: code/data from the executable, fixed-size stack with guard page (to prevent overflowing), expandable heap. This is how the user part of the process is organized.
The process space also has the kernel code/data beginning at the address KERNBASE (2GB). This part contains kernel code/data, free pages maintained by the kernel, and some space reserved for the I/O devices.
The page table of a process contains two sets of PTEs.
- The user entries map low virtual addresses to the physical memory sued by the process for its code/data/stack/heap.
- The kernel entries map high virtual addresses to physical memory containing OS code and data structures. These entries are identical across all processes.
A process can only access memory mapped by its own page table.
OS page table mappings
The OS code/data structures are a part of the virtual address space of every process. The page table entries map high virtual addresses (2GB to 2GB + PHYSTOP) to OS code/data in physical memory (~0 to PHYSTOP). This part contains the kernel code/data, I/O devices, and primarily free pages. Note that there is only a single copy of OS code in memory, mapped into all process page tables.
Can’t we directly access the OS code using its physical address? No. With paging and MMU, the physical memory can only be accessed by assigning a virtual address. During a trap, the same page table can be used to access the kernel. If the OS is not a part of the virtual address space, we would have had to use a new page table during trap which is cumbersome (?).
Some of the aforementioned free pages in the OS memory are assigned to processes. Suppose a physical frame P is initially mapped into the kernel part of the address space at virtual address V ( we will have V = P + KERNBASE). When assigned to a user process, this piece of memory is assigned another virtual address U (< KERNBASE). This is because a user cannot utilize this free page unless the PTE is in the userspace. Hence, the same frame P is mapped twice into the page table! The kernel and user access the same memory using different virtual addresses.
What is going on above?
Every byte of RAM can consume 2 bytes of virtual address space, so xv6 cannot use more than 2GB of RAM. Actual kernels deal with this better. For example, the kernel page is deleted when a user page is created.
Maintaining free memory
After bootup, RAM contains the OS code/data and free pages. The OS collects all the free pages into a free list called run to be assigned to the user processes. This free list is a linked list, and the pointer to the next free page is embedded within the previous free page.
Any process that needs a free page uses kalloc() to get a free page. Memory is freed up using kfree(). We need to add the free page to the head of the free list and update the free list pointer. Take a look at the codes for this part.
Summary of virtual memory in xv6
xv6 only has virtual addressing, no demand paging. There is a 2 tier page table, outer pgdir, and inner pages tables. The process address space has
- User memory image at low virtual addresses
- Kernel code/data mapped at high virtual addresses.
Lecture 28 - Memory Management of user processes in xv6
The user process needs memory pages to build its address space. Every process requires memory for memory image and page table. The free list of the kernel allocates this memory using kalloc. The new virtual address space for a process is created during init process creation, fork system call, and exec system call. The existing virtual address space is modified using the sbrk system call (to expand heap). The page table is constructed in the following manner:
- We start with a single page for the outer page directory
- We allocate inner page tables as and when needed.
Functions to build page table
Every page table begins setting up the kernel mappings in setupkvm. The outer pgdir is allocated. The kernel mappings defined in kmap are added to the page table by calling mappages. After setupkvm, user page table mappings are added.
// This table defines the kernel’s mappings, which are present in
// every process’s page table.
static struct kmap {
void *virt;
uint phys_start;
uint phys_end;
int perm;
} kmap[] = {
{ (void*)KERNBASE, 0, EXTMEM, PTE_W}, // I/O space
{ (void*)KERNLINK, V2P(KERNLINK), V2P(data), 0}, // kern text + rodata
{ (void*)data, V2P(data), PHYSTOP, PTE_W}, // kern data + memory
{ (void*)DEVSPACE, DEVSPACE, 0, PTE_W}, // more devices
};
// Set up kernel part of a page table.
pde_t*
setupkvm(void)
{
pde_t *pgdir;
struct kmap *k;
if((pgdir = (pde_t*)kalloc()) == 0)
return 0;
memset(pgdir, 0, PGSIZE);
if (P2V(PHYSTOP) > (void*)DEVSPACE)
panic("PHYSTOP too high");
for(k = kmap; k < &kmap[NELEM(kmap)]; k++)
if(mappages(pgdir, k−>virt, k−>phys_end − k−>phys_start,
(uint)k−>phys_start, k−>perm) < 0) {
freevm(pgdir);
return 0;
}
return pgdir;
}
The page table entries are added by mappages. The arguments are page directory, range of virtual addresses, physical addresses to map to, and permissions of the pages. This function walks the page table for each page, gets the pointer to PTE via the function walkpgdir, and fills it with physical address and permissions. The function walkpgdir walks the page table and returns the PTE of a virtual address.
// Return the address of the PTE in page table pgdir
// that corresponds to virtual address va. If alloc!=0,
// create any required page table pages.
static pte_t *
walkpgdir(pde_t *pgdir, const void *va, int alloc)
{
pde_t *pde;
pte_t *pgtab;
pde = &pgdir[PDX(va)];
if(*pde & PTE_P){
pgtab = (pte_t*)P2V(PTE_ADDR(*pde));
} else {
if(!alloc || (pgtab = (pte_t*)kalloc()) == 0)
return 0;
// Make sure all those PTE_P bits are zero.
memset(pgtab, 0, PGSIZE);
// The permissions here are overly generous, but they can
// be further restricted by the permissions in the page table
// entries, if necessary.
*pde = V2P(pgtab) | PTE_P | PTE_W | PTE_U;
}
return &pgtab[PTX(va)];
}
// Create PTEs for virtual addresses starting at va that refer to
// physical addresses starting at pa. va and size might not
// be page−aligned.
static int
mappages(pde_t *pgdir, void *va, uint size, uint pa, int perm)
{
char *a, *last;
pte_t *pte;
a = (char*)PGROUNDDOWN((uint)va);
last = (char*)PGROUNDDOWN(((uint)va) + size − 1);
for(;;){
if((pte = walkpgdir(pgdir, a, 1)) == 0)
return −1;
if(*pte & PTE_P)
panic("remap");
*pte = pa | perm | PTE_P;
if(a == last)
break;
a += PGSIZE;
pa += PGSIZE;
}
return 0;
}
Fork: copying the memory image
The copyuvm function is called by the parent to copy the parent’s memory image to the child. Check out fork’s code here. This function starts out by creating a new page table for the child. Then, it has to walk through the parent’s memory image page by page and copy it to the child while adding the child page table mappings.
copyuvm(pde_t *pgdir, uint sz)
{
pde_t *d;
pte_t *pte;
uint pa, i, flags;
char *mem;
if((d = setupkvm()) == 0)
return 0;
for(i = 0; i < sz; i += PGSIZE){
if((pte = walkpgdir(pgdir, (void *) i, 0)) == 0)
panic("copyuvm: pte should exist");
if(!(*pte & PTE_P))
panic("copyuvm: page not present");
pa = PTE_ADDR(*pte);
flags = PTE_FLAGS(*pte);
if((mem = kalloc()) == 0)
goto bad;
memmove(mem, (char*)P2V(pa), PGSIZE);
if(mappages(d, (void*)i, PGSIZE, V2P(mem), flags) < 0) {
kfree(mem);
goto bad;
}
}
return d;
bad:
freevm(d);
return 0;
}
For each page in the parent,
- We fetch the PTE and gets its physical address and permissions
- We allocate a new page for the child and copy the parent’s page’s contents to the child’s new page.
- Then, we add a PTE from the virtual address to the physical address of the new page in the child page table.
Real operating systems do copy-on-write fork - The child page table also points to the parent pages until either of them modifies the pages. Here, xv6 creates separate memory images for the parent and the child right away.
Growing memory image - sbrk
Initially, the heap of a process is empty, and the program break is at the end of the stack. The sbrk system call is invoked by malloc to expand the heap. The allocuvm allocates new pages and adds mappings into the page table for the new pages to grow memory. Whenever the page table is updated, we must update the cr3 register and TLB (using switchuvm).
The allocuvm function walks through the new virtual addresses to be added in the page-sized chunks.
Exec System call
Refer to the code in xv6 documentation. It reads the ELF (the new executable) binary file from the disk into memory. It starts with a new page table and adds mappings to the new executable pages to grow the virtual address space. So far, it hasn’t overwritten the old page table. Once the executable is copied to the memory image, we allocate 2 pages for stack (1 for guard page whose permissions are cleared, and upon accessing will trap). All the exec arguments are pushed on the user stack for the main function of the new program.
If no errors have occurred so far, we switch to the new page table. We set eip in trapframe to start at the entry point of the new program.
Live Session 6
-
Why do we have
walkpgdirincopyuvm?Aren’t page tables contiguous? Self-answered: Thecopyuvmfunction copies entire pages. Thewalkpgdiris only for the outer page directory.walkpgdirsimply returns the PFN of the input VPN, and allocates a new inner page if necessary. Therefore, there is no redundancy! -
Why is the kernel allocation memory from its free pages to the user processes? The purpose of double mapping in virtual space.
Think of it this way. The true RAM of your computer is only from
0toPHYSTOP. Every piece of allocated memory comes from0toPHYSTOP, and this maps to both kernel and user part of the memory image of a process. Yes, it’s naive! Modern Operating systems have other optimizations. -
In line 2600 of
forksystem call, why do we copy trapframe again?uvmincopyuvmmeans user virtual memory. This function only copies the user part of the memory. The kernel stack and other structures are built usingallocproc. You have to manually copy thestruct procdata or any other kernel data for that matter. -
Note. A process can think it has \(1\)TB of memory too! The present bit takes care of this.
-
The OS does not take part in every memory access. Why?
The OS is only in play when the process is being initialised, page faults, or when it is being context switched. Otherwise, the MMU + TLB take care of the address translations. Therefore, the MMU also needs to perform checks on the virtual address and ensure the query is not invalid.
Lecture 12 - Threads and Concurrency
So far, we have studied single-threaded programs. That is, there is only a single thread of execution. When a given memory image is being executed in the memory, there is only a single execution flow. A program can also have multiple threads of execution.
Firstly, what is a thread? A thread is like another copy of a process that executes independently. In a multi-threaded program, we have multiple threads of execution. For example, a 2-thread process will have 2 PCs and 2 SPs. Threads share the same address space. However, each thread has a separate PC to run over different parts of the program simultaneously. Each thread also has a separate stack for independent function calls.
Process vs. Thread
When a parent process P forks a child C, P and C do not share any memory. They need complicated IPC mechanisms. If we want to transfer data while running different parts of the process simultaneously, we need extra copies of code and data in memory. It’s very complicated to handle simultaneous execution using processes.
However, if a parent P executes two threads T1 and T2, they share parts of the address space. The process can use global variables for communication. This method also has a smaller memory footprint.
In conclusion, threads are like separate processes, except they use the same address space.
Why threads?
Why do we want to run different parts of the same program simultaneously? Parallelism - A single process can effectively utilize multiple CPU cores. There is a difference between concurrency and parallelism.
- Concurrency - Running multiple threads/ processes in tandem, even on a single CPU core, by interleaving their executions. Basically, all the stuff we’ve learned in the single thread execution.
- Parallelism - Running multiple threads/processes in parallel over different CPU cores.
We can exploit parallelism using multiple threads. Even if there is no scope for parallelism, concurrently running threads ensures effective use of CPU when one of the thread blocks.
Scheduling threads
The OS schedules threads that are ready to run independently, much like processes. The context of a thread (PC, registers) is saved into/ restored from a thread control block (TCB). Every PCB has one or more linked TCBs. Threads that are scheduled independently by the kernel are called kernel threads. For example, Linux pthreads are kernel threads.
What are kernel threads?
In contrast, some libraries provide user-level threads. These are not very common. This fact implies that not all threads are kernel threads. The library multiplexes a larger number of user threads over a smaller number of kernel threads. The kernel of the process sees these threads as separate processes. Also, note switching between user threads has a low overhead (nothing like context switching). However, multiple user threads cannot be run in parallel. Therefore, user threads are not very useful.
What is going on in the above paragraph?
Creating threads using pthreads API
Here is a simple thread creating code.
# include <pthread.h>
int main(...)
{
pthread_t p1, p2;
int rc = pthread_create(&p1, NULL, fun1, "function_argument");
assert(rc == 0);
rc = pthread_create(&p2, NULL, fun2, "arg2");
assert(rc == 0);
// Join wait for the threads to finish
rc = pthread_join(p1, NULL); asssert(rc == 0);
rc = pthread_join(p2, NULL); asssert(rc == 0);
}
We usually want to run different threads for them to perform a job together. We do this using global variables. For example, suppose a function increments a global counter to 10. Suppose we run two threads for this function. The final counter value after the execution of both threads should be 20. Sometimes, it may be a lower value too! Why? An issue with threads.
When multiple threads access the same space of data, all weird things happen. For example, a wrong value is propagated across threads when the OS/CPU switches from one thread to another before the thread could save the new value in the global variable. The problem is depicted in the following example.
## Race conditions and synchronization
What just happened is called a race condition where concurrent execution led to different results. The portion of code that can lead to race conditions is known as the critical section. We need mutual exclusion, where only one thread should be executing the critical section at any given time. For this to happen, the critical section should execute like one uninterruptable instruction - atomicity of the critical section. How is this achieved? Locks.
Lecture 13 - Locks
We’ve concluded in the previous lecture that locks are the solution to the race conditions in threads. A lock variable helps in the exclusivity of the threads for protection.
lock_t mutex;
lock(&mutex);
// Critical Section
unlock(&mutex);
All threads accessing a critical section share a lock. One of the threads locks the section - owner of the lock. Any other thread that tries to lock cannot proceed further until the owner releases the lock. Locks are provided by the pthreads library.
Building a lock
Goals of a lock implementation
- Mutual exclusion
- Fairness - All threads should eventually get the lock, and no thread should starve
- Low overhead - Acquiring, releasing, and waiting for a lock should not consume too many resources.
Implementation of locks is needed for both user-space programs (e.g., pthreads library) and kernel code. Also, implementing locks needs support from hardware and the OS.
Is disabling interrupts enough?
Previously, the race condition issue arose due to an interrupt at the wrong moment. So can we simply disable interrupts when a thread acquired a lock and is executing a critical section? No! The following issues will occur in that case -
- Disabling interrupts is a privileged instruction, and the program can misuse it (e.g., run forever).
- It will not work on multiprocessor systems,since another thread on another core can enter the critical section.
Basically, we don’t want to give a user program much power after acquiring a lock. However, this technique is used to implement locks on a single process system inside the OS (trusted code, e.g., xv6).
Locks implementation (Failure)
Suppose we use a flag variable for a lock. Set the flag for acquiring the lock, and unset it for unlocking.
typedef struct __lock_t {int flag; } lock_t;
void init(lock_t *mutex)
{
mutex -> flag = 0;
}
void lock (lock_t *mutex)
{
while (mutex -> flag == 1)
; // spin-wait (do nothing)
mutex -> flag = 1;
}
void unlock (lock_t *mutex)
{
mutex -> flag = 0;
}
What are the problems here? The race condition has moved to the lock acquisition code! How? Thread 1 spins, the lock is released, spin ends. Suppose thread 1 is interrupted just before setting the flag. Now, thread 2 sets the flag to 1. However, thread 1 still thinks lock is not acquired and sets the flag to 1. Therefore, both the threads have locks, and there is no mutual execution.
Seeing the above implementation, it’s clear that we cannot implement locks only using software. Hence, we need hardware atomic instructions.
Hardware atomic instructions
Modern architectures provide hardware atomic instructions. For example, test-and-set - update a variable and return old value, all in one hardware instruction. We can design a simple lock using test-and-set.
void lock (lock_t *mutex)
{
while (TestAndSet(&lock -> flag, 1) == 1)
; // spin-wait (do nothing)
}
If TestAndSet(flag, 1) returns 1, it means the lock is held by someone else, so wait busily. This lock is called a spinlock - spins until the lock is acquired.
There is also a compare-and-swap instruction which checks the expected value with the current value. If both the values are equal, the value is set to the new value. We can also implement a spinlock using this instruction.
void lock(lock_t *lock) {
while(CompareAndSwap(&lock -> flag, 0, 1) == 1) ; //spin
}
Alternative to spinning
We can make the thread sleep instead of spinning and utilizing the CPU. A contending thread could simply give up the CPU and check back later. In literature, a mutex by itself means a sleeping mutex.
void lock(){
while(TestAndSet(&flag, 1) == 1)
yield(); // Name changes across OS
}
## Spinlock vs. mutex
Most user-space lock implementations are of sleeping mutex kind. However, the locks inside the OS are always spinlocks! Why? If we sleep in the OS code, we cannot context switch to another process. When OS acquires a spinlock -
-
It must disable interrupts (on that processor code) while the lock is held. Why? An interrupt handler could request the same lock and spin it forever - A deadlock situation.
What?
-
It must not perform any blocking operation - never go to sleep with a locked spinlock!
In general, we must use spinlocks with care and release them as soon as possible.
Usage of Locks
The user must acquire a lock before accessing any variable, or data structure shared between multiple threads of a process. This implementation is called a thread-safe data structure. All the shared kernel data structures must also be accessed only after locking.
Coarse-grained vs. fine-grained locking - One big lock for all the shared data vs. separate locks for each variable. Fine-grained locking allows more parallelism but is harder to manage. The OS only provides locks, but the proper locking discipline is left to the user.
Lecture 14 - Condition variables
Locks allow one type of synchronization between threads. There is another typical requirement in multi-threaded applications. It is known as waiting and signaling. Here, one thread might want another thread to finish the job and signal to the original thread when the job is executed. We can accomplish such synchronization using busy-waiting, but it is inefficient. Therefore, most modern OS have a new synchronization primitive - condition variables (as called in pthreads).
Condition Variables
A condition variable (CV) is a queue that a thread can be placed into when waiting on some condition. Another thread can wake up the waiting thread by signaling CV after making the condition true. pthreads provides CV for user programs and also for kernel threads. There are two kinds of signaling -
- A signal wakes up a single thread
- A signal broadcast that wakes up all the waiting threads.
Here is an example utilizing CV -
int done = 0;
pthread_mutex_t m = PTHREAD_MUTEX_INITIALIZER;
pthread_cond_t c = PTHREAD_COND_INITIALIZER;
void thr_join(){
Pthread_mutex_lock(&m); // Line *
while(done == 0)
Pthread_cond_wait(&c, &m); //Parent thread goes to sleep
Pthread_mutex_unlock(&m);
}
void thr_exit() {
Pthread_mutex_lock(&m);
done = 1;
Pthread_cond_signal(&c); // Send a signal
Pthread_mutex_unlock(&m);
}
void *child (void *arg)
{
printf("child\n");
thr_exit();
return NULL;
}
int main ()
{
printf("Parent - begin\n");
pthread_t p;
Pthread_create(&p, NULL, child, NULL);
thr_join;
printf("Parent - end\n");
}
Doesn’t the parent already wait in line * if the child is executed before?
What if the parent acquires lock first? The wait function releases the lock. See below.
In the above example, it doesn’t matter which thread (child/parent) gets executed first. The flow is still the same as expected. Note that it is always better to check the condition (in the while loop) before waiting. Otherwise, the parent thread will not be woken up.
Why do we use a while instead of if? To avoid corner cases of thread being woken up even when the condition is not true (maybe an issue with some implementation). This is a good programming practice.
Why do we hold locks before checking the condition? What if we didn’t use a lock? There would be a race condition for a missed wakeup
- Parent checks done to be 0, decides to sleep and is then interrupted.
- The child runs, sets done to 1, signals, but no one is sleeping.
- The parent now resumes and goes to sleep forever.
Therefore, a lock must be held when calling wait and signal with CV. The wait function releases the lock before putting the thread to sleep, so the lock is available for the signaling thread.
Producer/Consumer Problem
This setting is a common pattern in multi-threaded programs. There are two pr more threads - producer(s) and consumer(s) which share a shared buffer (having a finite size). We need mutual exclusion in the buffer, and also a signaling mechanism to share information.
For example, in a multi-threaded web server, one thread accepts requests from the network and puts them in a queue. The worker threads get requests from this queue and process them. Here’s how we implement this -
cond_t empty, fill;
mutex_t mutex;
void *producer(void *arg)
{
int i;
for (i = 0; i < lopps; i++)
{
Pthread_mutex_lock(&mutex);
while(count == MAX)
Pthread_cont_wait(&empty, &mutex);
put(i);
Pthread_cond_signal(&fill);
Pthread_mutex_unlock(&mutex);
}
}
void *consumer(void *arg)
{
int i;
for (i = 0; i < loops, i++)
{
Pthread_mutex_lock(&mutex);
while(count == 0)
Pthread_cond_wait(&fill, &mutex);
int tmp = get();
Pthread_cond_signal(&empty);
Pthread_mutex_unlock(&mutex);
printf("%d\n", tmp);
}
}
Live Session 7
-
The OS does not raise a trap when you access a shared variable protected using a lock in another thread. Why? The usage of locks is wholly left to the user. The OS cannot see these variables too! A lock is nothing but another variable.
-
Condition variable in a queue? That was a wrong statement in the slides. The implementation of the condition variables determines which thread is woken up first among the threads that are waiting. Even all of the threads can wake up at once. For example, in xv6, all the threads are woken up at once.
-
Why
ifinstead of awhile? If all the waiting threads are woken up, then usingifmight cause a problem!whilein case of spurious wake-ups. -
Why spinlocks in the OS code? The OS itself cannot yield itself to anybody else. It cannot rely on other processes to wake it up in case the lock is not acquired. The alternative to the spinlock implementation is using hardware help. The OS can wake up when the hardware gives an interrupt (after the lock is released). However, we don’t have this support.
-
Why does disabling interrupts on a single core work? This method is only for OS that works on a single thread. The OS can interrupt the user programs. However, only hardware can interrupt the OS. So, when you disable interrupts, there is no way the OS can be interrupted.
However, if you have a multicore architecture, another thread can access the shared variables from another core (not using locks here, just talking about disabling interrupts).
-
The
sleepfunction releases the lock. However, when the process wakes up, it reacquires the lock. So, there is no double-freeing. The doubt was asked based on this context. -
Do we need to disable interrupts on all cores for smooth execution of OS code? However, you need not disable interrupts on other cores. The OS code that needs to access this space has to acquire the lock (which is not possible as the original thread is the owner) and wait before accessing the shared space.
We said disabling interrupts won’t work in multicore architecture (two points before). But that situation was not considering locks, and we have locks in this case.
What happens if you disable interrupts on all cores anyway?
-
What do we do if a serious interrupt occurs when interrupts are disabled?
-
Once a process commits to a core, it cannot run on another core in between. It has to finish on the current core itself.
-
The concept of user threads and kernel threads. User-level threading libraries create an illusion of multiple threads. However, the kernel does not see these as independent processes but as a single process. For example, the
pthreadlibrary is only for kernel threads. It is not an illusion. Nevertheless, even with a user-level thread, you can get interrupted at the wrong time. Therefore, we need locks even in the user-level illusionary threads. -
int nis an atomic instruction.
Lecture 15 - Semaphores
We are going to study another synchronization primitive called semaphores.
What is a semaphore?
They are very similar to condition variables. It is a variable with an underlying counter. You can call two functions on a semaphore variable -
-
up/postincrement the counter -
down/waitdecrement the counter and block the calling thread if the resulting value is negative.
The above two functions represent the interface to a semaphore. A semaphore with an initial value of 1 acts as a simple lock. That is, a binary semaphore is equivalent to a mutex. Here is a simple usage of a binary semaphore.
sem_t m;
sem_init(&m, 0, X); // X can be 1 here
sem_wait(&m);
// Critical section
sem_post(&m);
Semaphores for Ordering
They can be used to set the order of execution between threads like a CV. This example is similar to what we have seen before with the “parent waiting for child” example. An important point to note here is that the semaphore is initialized to 0 here. Why? Because the parent has to wait for the child to finish.
sem_t s;
void* child (void *arg)
{
printf("child\n");
sem_post(&s);
return NULL; // Line *
}
int main(int argc, chara *argv[])
{
sem_init(&s, 0, 0);
printf("parent: begin\n");
pthread_t c;
Pthread_create(&c, NULL, child, NULL);
sem_wait(&s);
printf("parent: end\n");
return 0;
}
What if line * had a print statement? Where would that get printed?
Therefore, it is essential to correctly determine the initial value of the semaphore for correct behavior.
Producer/Consumer Problem (1)
Let us revisit this problem in the context of semaphores. We need one semaphore to keep track of empty slots and another to keep track of full slots. The producer waits if there are no more empty slots, and the consumer waits if there are no more full slots. Also, we need another semaphore to act as a mutex for the buffer. Here is how these variables are initialized.
int main(int argc, char *argv[])
{
// ...
sem_init(&empty, 0, MAX);
sem_init(&full, 0, 0);
sem_init(&mutex, 0, 1); // Thumb rule - Locks are initialized with value 1
// ...
}
There is a subtle point in this example. Consider the producer function.
void* producer (void *arg)
{
for(int i = 0; i < loops; ++i)
{
sem_wait(&empty);
sem_wait(&mutex);
put(i);
sem_post(&mutex);
sem_post(&full);
}
}
* What if we acquire mutex before checking the other semaphores? It would result in a deadlock situation. The waiting thread can sleep with the mutex, and the signaling thread can never wake it up!
Lecture 16 - Concurrency Bugs
In general, writing multi-threaded programs is tricky. These bugs are non-deterministic and occur based on the execution order of threads - challenging to debug. We shall discuss two types of bugs in this lecture and methods to prevent them.
- Deadlocks - Threads cannot execute any further and wait for each other. These are very dangerous.
- Non-deadlock bugs - Non-deadlock, but the results are incorrect when the threads execute.
Non-deadlock bugs
These are of two types -
-
Atomicity bugs - Occur due to false atomicity assumptions that are violated during the execution of concurrent threads. We fix these bugs using locks!
Example -
Thread 1:: if (thd -> proc_info) { fputs(thd -> proc_infor, ...); } Thread 2:: thd -> proc_info = NULL;This situation is basically a race condition! Although, the crucial point to note here is atomicity bugs can occur, not just when writing to shared data, but even when reading it!
Always use a lock when accessing shared data.
-
Order-violation bugs - Occur when desired order of memory accesses is flipped during concurrent execution. We fix these using condition variables.
Thread 1:: void init() { mThread = PR_CreateThread(mMain, ...); } Thread 2:: void mMain(...) { mState = mThread -> State; }Thread 1 assumes that Thread 2 had been executed before, and this causes an error.
Deadlock bugs
Here is a classic example of a deadlock situation.
// Thread 1:
pthread_mutex_lock(L1);
pthread_mutex_lock(L2);
// Thread 2:
pthread_mutex_lock(L2);
pthread_mutex_lock(L1);
Deadlock may not always occur in this situation. It only occurs when the executions overlap, and a context switch occurs from a thread after acquiring only one lock. It is easy to visualize these situations using a dependency graph. A cycle in a dependency graph causes a deadlock situation.
When does a deadlock occur?
- Mutual exclusion - A thread claims exclusive control of a resource (e.g., lock)
- Hold-and-wait - The thread holds a resource and is waiting for another
- No preemption - A thread cannot be made to give up its resource (e.g., cannot take back a lock)
- Circular wait - There exists a cycle in the resource dependency graph.
All of the above conditions must hold for a deadlock to occur.
Isn’t (4) by itself enough for a deadlock? the cycle must be reachable
To prevent a circular wait, we need to acquire locks in a particular fixed order! e.g., both threads acquire L1 before L2 in the previous example.
To do this, we need a total (partial) ordering of locks. For example, this ordering can be done via the address of lock variables.
Preventing hold-and-wait
Acquire all locks at once using a master lock. This way, you will hold all locks or none of them. However, this method may reduce concurrent execution and performance gains. Think.
Other solutions to deadlocks
Deadlock avoidance - If the OS knows which process needs which locks, it can schedule the processes in that deadlock will not occur. One such algorithm is Banker’s algorithm. But it is impractical in real life to assume this knowledge.
Detect and recover - Reboot system or kill deadlocked processes. There is no standard implementation to tackle deadlocks. :(
Live Session 8
- If you disable interrupts on all cores anyway, nothing bad happens. There are no emergency interrupts which might destroy your system if not handled immediately.
- semaphores no need to acquire lock. cv need to acquire lock. cv reacquires lock too.
- no context switch on post!
Synchronization problems
Question 26
Allowing N guests all at once into the house.
// host
lock(m)
while(guest_count < N)
wait(cv_host, m)
openDoor()
signal(cv_guest)
// signalbroadcast too
unlock(m)
// Guests code?
lock(m)
guest_count++
if(guest_count == N)
signal(cv_host)
wait(cv_guest, m)
signal(cv_guest) // To signal other threads
// above line not needed if singal braodcast is there
unlock(m)
enterHouse()
Whenever you write code, start with the wait signals. Then, put the logic in place and ensure there are no deadlocks. Also, pair up every wait with a signal.
Question 25
Passenger thread given -
down(mutex)
waiting_count++
up(mutex)
down(bus_arrived)
board()
up(passenger_boarded)
Bus code?
down(mutex)
N = min(waiting_count, K)
for i = 1 to N
up(bus_arrived)
down(passenger_boarded)
waiting_count -= N;
up(mutex)
Lecture 29 - Locking in xv6
Why do we need locking in xv6? There are no threads in xv6! Therefore, no two user programs can access the same userspace memory image. However, there is a scope for concurrency in xv6 kernel. For example, two processes in the kernel mode on different CPU cores can access the same data structures. Another example where this sort of thing happens is in the case of interrupts. When an interrupt occurs while processing the trap of another process, the new interrupt handler can access the previous kernel code. Therefore, we need spinlocks to protect critical sections in xv6. xv6 also has a sleeping lock which is built on spinlock.
Spinlocks in xv6
// Mutual exclusion lock.
struct spinlock {
uint locked; // Is the lock held?
// For debugging:
char *name; // Name of lock.
struct cpu *cpu; // The cpu holding the lock.
uint pcs[10]; // The call stack (an array of program counters)
// that locked the lock.
};
/////////////////////////////////
void
acquire(struct spinlock *lk)
{
pushcli(); // disable interrupts to avoid deadlock.
if(holding(lk))
panic("acquire");
// The xchg is atomic.
while(xchg(&lk−>locked, 1) != 0)
;
// Tell the C compiler and the processor to not move loads or stores
// past this point, to ensure that the critical section’s memory
// references happen after the lock is acquired.
__sync_synchronize();
// Record info about lock acquisition for debugging.
lk−>cpu = mycpu();
getcallerpcs(&lk, lk−>pcs);
}
Locks are acquired using xchg x86 atomic instruction. It is similar to test-and-set we’ve seen before. The xchg instruction sets the lock variable to 1 and returns the previous value. Remember, value of 1 means locked! Also, note that we need to disable interrupts on the CPU core before spinning for lock. It is okay for another process to spin for this lock on another core. This is because, the lock will be eventually released by this core (no deadlock can occur).
Disabling interrupts
Interrupts are disabled using pushcli. The interrupts must stay disabled until all locks are released. pushcli disables interrupts on the first lock acquire, and increments count for future locks. Then, popcli decrements count and reenables interrupts only when count is zero.
ptable.lock()
The process table is protected by this lock. Normally, a process in kernel mode acquires ptable.lock, changes ptable, and then release the lock. However, during a context switch, from process P1 and P2, the ptable structure is changed continuously and repeatedly. So when do we release the lock? P1 acquires the lock, switches to scheduler, switches to P2, and then finally P2 releases the lock. This is a special case where one process acquires the lock and another releases it.
Every function that calls sched will do so with ptable.lock held. sched is called from yield, sleep, and exit. Every function that swtch switches to will release ptable.lock. swtch also returns to
- Yield, when switching from process that is resuming after yielding is done
- Sleep, when switching in a process that is waking up after sleep
- Forkret for newly created processes
Thus, the process of forkret is to release ptable.lock after context switch, before returning to trapret.
What about the scheduler? We enter the scheduler with the lock held! Sometimes, the scheduler releases the lock (after it loops over all processes), and then reacquires it. Why does it do this? Whenever the lock is held, all interrupts are disabled. All processes might be in a blocked state waiting for interrupts. Therefore, the lock must be released periodically enabling interrupts and allowing process to become runnable.
Lecture 30 - Sleep and Wakeup in xv6
Consider the following example. A process P1 in kernel mode gives up the CPU to block on an event. For e.g., reading data from disk. Then, P1 invokes sleep which calls sched. Another process P2 in kernel mode calls wakeup when an event occurs. This function marks P1 as runnable so that the scheduler loop switches to P1 in the future. For e.g., disk interrupt occurs while P2 is running.
How does P2 know which process to wake up? When P1 sleeps, it sets a channel (void* chan) in its struct proc, and P2 calls wakeup on the same channel. This channel is any value known to both P1 and P2. Example: The channel value for a disk read can be address of a disk block.
A spinlock protects the atomicity of sleep: P1 calls sleep with some spinlock L held, P2 calls wakeup with same spinlock L held. Why do we need this setup?
- Eliminating missed
wakeupproblem that arises due to P2 issuing wakeup between P1 deciding to sleep and actually sleeping. - Lock L is released after sleeping, available for wakeup
- Similar concept to condition variables studied before.
The Sleep calls sched to give up the CPU with ptable lock held. The arguments to sleep are channel and a spinlock (not ptable.lock). sleep has to acquire ptable.lock, release the lock given to sleep (to make it available for wakeup). Unless lock given is ptable.lock itself, in which case no need to acquire the lock again. One of the two locks is always held!
When the control returns back to sleep, it reacquires the spinlock.
Why reacquire?
Wakeup function
This is called by another process with lock held (same lock as when sleep was called). Since this function changes ptable, ptable.lock is also held. Now, this function wakes up all process sleeping on a channel in the ptable. It is also a good idea to check if the condition is still true upon waking up (use while loop while calling sleep).
Example: pipes
Two process are connected by a pipe (producer consumer). Addresses of pipe structure variables are channels (same channel known to both). There is a pipe lock given as input to sleep.
Example: wait and exit
If wait is called in parent while children are still running, parent calls sleep and gives up the CPU. Here, channel is parent struct proc pointer, and lock is ptable.lock. In exit, the child acquires ptable.lock and wakes up the sleeping parent. Notice that here the lock give to sleep is ptable lock, because parent and child both access ptable (sleep avoids double locking, doesn’t acquire ptable.lock if it already held before calling sleep).
Why is terminated process memory cleaned up by the parent? When a process calls exit, CPU is using its memory (kernel stack is in use, cr3 is pointing to page table) so all this memory cannot be cleared until the terminated process has been taken off the CPU. Therefore, we need wait.
Live Session 9
- What if 2 threads on different CPU cores perform
test-and-set? This is ensured on the micro-architectural level. These are called cache coherence protocols. Memory can only be modified by a single core at a given time. Two or more cores cannot edit a variable simultaneously. Therefore, atomicity at the CPU level is guaranteed. - Why don’t we use sleep locks everywhere? The context switch overhead might be more than the wait time in sleeping locks. Suppose we have a single core, and a process on this core is spinning for a lock. Since there are no other cores, the lock owner cannot release lock at this instant. What happens here? The process will keep spinning until it eventually has to yield the CPU.
- In semaphores, every
upshould wake up one thread!downchecks if the counter is negative and goes to sleep. Whenupsignals these sleeping threads, they wake up even though the counter is negative. - Interrupts are queued up when interrupts arrive on an interrupt-disabled core.
-
myproc()? In xv6, we have an assumption that no processes on any other core edit thestruct procof the running process. Therefore, we don’t need any locks to access thestruct procof the running process. - The reacquiring of the second lock in
sleepis not necessary but is a convention. Why do we send this lock tosleep? To preserve the atomicity ofsleep! - How does an interrupt know the channel to wakeup a process? Every interrupt handler has a logic for deciphering the channel. For ex, a disk read interrupt handler knows that the sector of the address read is the channel.
- Missed wakeups cause deadlocks!
Lecture 17 - Communication with I/O devices
I/O devices connect to the CPU and memory via a bus. For example, a high speed bus, e.g., PCI and others like SCSI, USB, SATA, etc. The point of connection to the system is called the port.
Simple Device Model
Devices are of two types -
- Block devices - The stored a set of numbered blocks. For ex, disks.
- Character devices - Produce/consume stream of bytes. For ex, keyboard.
All these devices expose an interface of memory registers. These registers tell the current status of the device, command to execute, and the data to transfer. The remaining internals of the device are usually hidden. There might be a CPU, memory, and other chips inside the device.
Interaction with the OS
There are explicit I/O instructions provided by the hardware to read/write to registers in the interface. For example, on x86, in and out instructions can be used to read and write to specific registers on a device. These are privileged instructions accessed by the OS. A user program has to execute a system call in order to interact with the devices.
The other way to do this is via the memory mapped I/O. The devices makes registers appear like memory locations. The OS simply reads and writes from memory. The underlying memory hardware routes the accesses to these special memory addresses to devices.
What memory hardware?
Simple execution of I/O requests
While STATUS == BUSY
; //wait
Write data to DATA register
Write command to COMMAND register
White STATUS == BUSY
; // wait till device is done with request
The above pseudocode is a simple protocol to communicate with an I/O device. The polling status to see of device is ready wastes a lot of CPU cycles. The Programmed I/O explicitly copies data to/from device. The CPU need to be involved in this task.
Interrupts
As polling wastes CPU cycles, the OS can put the process to sleep and switch to another process. When the I/O request completes, the device raises an interrupt.
The interrupt switches process to kernel mode. The Interrupt Descriptor Table (IDT) stores pointers to interrupt handlers (interrupt service routines). The interrupt (IRQ) number identifies the interrupt handler to run for a device.
The interrupt handler acts upon device notification, unblocks the process waiting for I/O, and starts the next I/O request. Also, handling interrupts imposes kernel mode transition overheads. As a result, polling may be faster than interrupts if devices is fast.
Direct Memory Access
The CPU cycles are wasted in copying data to/from device. Instead, we can use a special piece of hardware (DMA engine, seen in CS305) copies from main memory to device. The CPU gives DMA engine the memory location of data. In case of a read, the interrupt is raised after DMA completes. On the other hand, in case of a write, the disk starts writing after DMA completes.
Device Driver
The part of the OS code that talks to the specific device, gives commands, handles interrupts etc. Most of the OS code abstracts the device details. For example, the file system code is written on top of a generic block interface. the underneath implementation is done via the device drivers.
Lecture 18 - Files and Directories
The file abstraction
A file is simply a linear array of bytes, stored persistently. It is identified with a file name and also has a OS-level identifier - inode number.
A directory contains other subdirectories and files, along with their inode numbers. A directory is stored like a file whose contents are filename-to-inode mappings. You can think of a directory as a special type of file.
Directory tree
Files and directories are arranged in a tree, start with root (/).
Operations on files
We can create a file using the open system call with a flag to create. It returns a number called file descriptor which is used as a file handle in the program.
int fd = open("foo", O_CREAT|O_WRONLY|O_TRUNC, S_IRUSR|S_IWUSR);
We also open an existing file with the same system call. This must be done before reading or writing to a file. All other operations on files use the file descriptor. Finally, the close system call closes the file.
Other operations on a file are -
-
read/writesystem calls. These occur sequentially by default. Successive read/write calls fetch from the current offset. The arguments to these functions are file descriptor, buffer with data and size. - To read/write at a random location in the file, we use
lseeksystem call that lets us seek to a random offset. - Writes are buffered in memory temporarily and are flushed using
fsync. - There are other operations to rename files, delete (unlink) files, or get statistics of a file.
Operations on directories
Directories can also be accessed like files. For example, the ls program opens and reads all directory entries. A directory entry contains file name, inode number, type of file, etc.
Note. All the shell commands are simply C programs compiled into executables.
Hard Links
Hard linking creates another file that points to the same inode number (and hence, same underlying data). If one file is deleted, file data can be accessed through the other links! inode maintains a link count, and the file data is deleted only when no further links exist to the data. You can only unlink, and the OS decides when to delete the data.
Soft links or symbolic links
Soft link is a file that simply stores a pointer to another filename. However, if the main file is deleted, then the link points to an invalid entry - dangling reference.
Mounting a filesystem
Mounting a filesystem connects the files to a specific point in the directory tree. Several devices and file systems are mounted on a typical machine and are accessed using mount command.
Memory mapping a file
There exists an alternate way of accessing a file, instead of using file descriptors and read/write system calls. mmap allocates a page in the virtual address space of a process. We can ask for an anonymous page to store program data or a file-backed page that contains data of a file. When a file is mmaped, file data is copied into one or more pages in memory and can be accessed like any other memory location in the program. This way, we can conveniently read/write into the file from the program itself.
Lecture 19 - File System Implementation
A file system is a way of organization of files and directories on a disk. An OS has one or more file systems. There are two main aspects of a file system -
- Data structures to organize data and metadata on the disk.
- Implementation of system calls like open, read, write, etc. using the data structures.
Usually, disks expose a set of blocks - of size 512 bytes in general. The file system organizes files onto blocks, and system calls are translated into reads and write on blocks.
A simple file system
The blocks are organized as follows -
- Data blocks - File data stored in one or more blocks.
- Metadata such as location of data blocks of a file, permissions, etc. about every file stored in the inode blocks. Each block has one or more inodes.
- Bitmaps - Indicate which inodes/data blocks are free.
- Superblock - Holds a master plan of all other blocks (which are inodes, which are data blocks, etc.)
inode table
Usually, inodes (index nodes) are stored in an array. Inode number of a file is index into this array. What does an inode store?
- File metadata - Permissions, access time, etc.
- Pointers (disk block numbers) of the file data.
inode structure
The file data need not be stored contiguously on the disk. It needs to be able to track multiple block number of a file. How does an inode track disk block numbers?
- Direct pointers - Numbers of first few blocks are sored in the inode itself (suffices for small files)
- Indirect blocks - For larger file, inode stores number of indirect block, which has block numbers of file data.
- Similarly, double and triple indirect blocks can be stores - multi-level index
File Allocation Table (FAT)
Alternate way to track file blocks. FAT stores next block pointer for each block. FAT has one entry per disk block, and the blocks are stored as a linked list. The pointer to the first block is stored in the inode.
Directory Structure
A directory stores records mapping filename to inode number. Linked list of records, or more complex structures (hash tables, binary search trees, etc.). A directory is a special type of file and has inode and data blocks (which store the file records).
Free space management
How to track free blocks? Bitmaps, for inodes and data blocks, store on bit per block to indicate if free or not. Also, we can have a free list in which the super block stores a pointer to the first free block and the free blocks are stored as a linked list. We can also use a more complex structure.
Opening a file
The file has to be opened to have the inode readily available (in memory) for future operations on the file. What happens during open?
- The pathname of the file is traversed, starting at root.
- inode of root is known, to bootstrap the traversal.
-
Then, we recursively fetch the inode of the parent directory, read its data blocks, get inode number of the relevant child, and fetch inode of a child.
- If a new file, new inode and data blocks will have to be allocated using bitmap, and the directory entry is updated.
Open file table
There is a global open file table which stores on entry for every file opened (even sockets, pipes). The entry point to in-memory copy of the inode (other data structures for sockets and pipes).
There also exists a per-process open file table which is an array of files opened by a process. The file descriptor number is an index into this array. The per-process table entry points to the global open file table entry. Every process has three file - standard in/out/err open by default (fd 0, 1, 2).
Open system call creates entries in both tables and return the fd number.
Reading and writing a file
For reading/writing a file
- Access in-memory inode via the file descriptor.
- Find the location of data block at current read/write offset. We get the locations from the inode itself.
- Fetch block from disk and perform operation.
- Write may need to allocate new blocks from disk using bitmap of free blocks.
- Update time of access and other metadata in inode.
Therefore, any access to a file accesses multiple data blocks - hence, we need multiple accesses to the disk.
Virtual File System
File systems differ in implementations of data structures - E.g., organization of file records in the directory. So, do the implementations of the system calls need to change across file systems? No! Linux supports virtual file system (VFS) abstraction. The VFS looks at a file system as objects (files, directories, inodes, superblock) and operations on these objects. The system call logic is written on these VFS objects.
Therefore, in order to develop a new file system, simply implement functions on VFS objects and provide pointers to these functions to the kernel. Syscall implementations need not change with the file system implementation details.
Disk Buffer cache
Results of recently fetched disk blocks are cached. The file system issues block read/write requests to block numbers via a buffer cache. If the block is in the cache, served from the cache and disk I/O is not required. Otherwise, block fetched to cache and returned to the file system.
What about inode updates?
Write are applied to cache block first. Synchronous/write-through cache write to disk immediately. Asynchronous/write-back caches stores dirty blocks in memory and writes back after a delay.
Usually, the page cache is unified in the OS. Free pages are allocated to both processes and disk buffer cache from a common pool. What are the benefits of caches?
- Improved performance due to reduced disk I/O.
- Single copy of block in memory - No inconsistency across processes
Second point? It’s fine.
Some applications like databases may avoid caching altogether, to avoid inconsistencies due to crashes - direct I/O.
Live Session 10
-
What is a file system? File system is just part of the OS code. All of the infrastructure related to files constitutes file system. You can implement the system calls related to the files in multiple ways. All of these different implementations are called “file systems.” However, the structure inside the disk can also refer to the file system (All follow VFS). What does it mean by OS can have more than one filesystems?
-
It take a finite amount of time to fetch the data from the interface of the disk to the internal memory. When the DMA is not implemented, the CPU has to oversee the data transfer from the disk to the Memory. Yes, context switching and all happens when a data query is called. However, the interrupt handler is invoked only when the data is ready (in the disk registers) in the disk itself. Once an interrupt is issued, the CPU copies data from the disk registers to multiple layers of caches and the main memory. DMA takes care of all this (The disk directly writes to the main memory).
DMA only accesses kernel buffers. User buffers are the
char* bufvariables in the user code. -
Advantage of memory mapped files? When you have to read a large chunk, you don’t have to wait for the disk to send multiple blocks. The file is already available in the memory. The disk buffer cache stores all the changes, and it has its own logic to flush, etc. The main advantage of memory-mapped files is avoiding the extra copy of the data in the memory! Any disk access is first copied into the disk buffer cache. These data blocks are then added to the process’ virtual address space. However, the data blocks are only present in the virtual address space when you use memory-mapped files. As in, the disk buffer cache’s pages are directly used in the page table of the process. On the other hand, if we use a read() system call, the data is copied into some buffer in the process. In any case, disk buffer cache is must!
-
Normal read/write - Get a block from the disk into the kernel data cache, copy the bytes into the user space buffer. In memory mapping, the user space buffer does not have a copy but a pointer to the kernel buffer directly. There exists a concept of block/page cache which is an advanced concept.
-
Mounting - Joining two trees by creating a new node that is the root of another directory tree.
-
We have different entries in file table when two processes open the same file to ensure concurrency and correctness. Two files can read/write simultaneously if there are two entries. However, a parent and the child will point to the same file entry! This is why STD ERR/IN/OUT are the same for all processes.
-
What is the use of the global file table? For the OS to keep track of all the open files in a central repository.
-
Why not store the offset in the process’ file descriptor array itself? We need to have some processes sharing the offsets and some to not share them. The implementation is difficult, but it can be done.
-
The indirect blocks are not counted as the data blocks of the process!
Lecture 31 - Device driver and block I/O in xv6
Any filesystem is built as multiple layers of abstraction in file systems -
- System call implementations - open, read, write.
- Operations on file system data structures - inodes, files, directories.
- Block I/O layer - in-memory cache of disk blocks.
- Device driver - communicates with hard disk to read/write blocks.
Disk blocks and buffers
Disk maintains data as 512-byte blocks. Any disk block handled by the OS is also backed up in the disk buffer (struct buf in kernel memory). This is basically a copy of disk block in the memory. All the struct bufs are stored in a fixed size Buffer cache called as bcache. This is maintained as a LRU linked list.
When we read from the disk, we assign buffer for the block number in the buffer cache, and the device driver sends read request to the disk controller. The disk controller raises an interrupt when the data is ready, and then the data is copied from the disk controller to the buffer cache - VALID flag is set after data is read.
When we write to the disk, we first write into the buffer cache, and then issue a request to the disk. The device driver copies data from the buffer to the disk controller, and the disk controller raises an interrupt when write is complete - DIRTY flag is set until disk is updated.
Device Driver
Processes that wish to read/write call the iderw function with buffer as the argument. If the buffer is dirty, it initiates a write request. If a buffer is invalid, then it places a read request. Requests are added to the queue and the function idestart issues requests after one another. The process sleeps until the request completes. The communication with the disk controller registers is done in idestart via in/out instructions we’ve seen before. This function knows all the register addresses of the devices - code is customized for every device.
When the disk controller completes read/write operation, it raises an interrupt
- Data is read from the disk controller intos the buffer using
ininstruction - The sleeping processes are woken up
- The next request from the queue is issued
All of this is done in ideintr function which is called via the trap function. Also, there is no support for DMA in x86. With a DMA, the data is copied by the disk controller into the memory buffers directly before raising an interrupt. However, the CPU has to oversee this in xv6 without the presence of the DMA.
so the
inslinstruction is run by the DMA in DMA-supported cores?
Disk buffer cache
All processes access the disk via the buffer cache. There exists only one copy of the disk block in cache, and only one process can access it at a time.
The process calls bread to read a disk block. This function in turn calls bget which returns buffer if it already exists in the cache and no other process using it (using locks). Otherwise, if valid buffer is not returned by bget, bread reads from the disk using iderw.
A process calls bwrite to write a block to disk, set dirty bit and request device driver to write. When done with the block, the process calls brelse to release the block and moves it to the head of the list.
Let’s delve into bget. It returns the pointer to the disk block if it exists in the cache. If the block is in cache and another process is using it, it sleeps until the block is released by the other process. However, if block is not in cache, it fins a least recently used non-dirty buffer and recycles it to use for this block.
What if all blocks are dirty?
panic!
The two goals achieved by the buffer cache are
- Recently used disk blocks are stored in the memory for future use.
- Disk block are modified by only one process at a time.
Logging layer
A system call can change multiple blocks at a time on the disk, and we want atomicity in case the system crashes during a system call. So, wither all changes are made or none is made. Logging ensures atomicity by grouping disk block changes into transactions
- Every system call starts a transaction in the log, write all changed disk blocks in the log, and commits the transaction.
- Later, the log installs the changes in the original disk blocks one by one.
- If a crash happens before the log is written fully, no changes are made. However, if a crash happens after the log entry is committed, the log entries are replayed when the system restarts after crash.
restart from the start or last left entry?
In xv6, changes of multiple system calls are collected in memory and committed to the log together. Actual changes happen to disk blocks only after the group transaction commits. The process must call log_write instead of bwrite during the system call. (?)
Lecture 32 - File system implementation in xv6
Disk layout
The disk in xv6 is formatted to contain a superblock (followed by the boot block), log (for crash recovery), inode blocks (multiple inodes packed per block), bitmap (indicating which data blocks are free), and, finally, the actual data blocks.
The disk inode contains block number of direct blocks and one indirect block. Also, directory is treated as a special file. The data blocks contain directory entries and the corresponding name-inode number mappings. The inode also stores the link count - number of directory entries pointing to a file inode.
In-memory data structures
Every open file has a struct file associated with it which contains some variables such as pointer to inode and pipe structure. All struct files are stored in a fixed size array called the file table (ftable). The file descriptor array of a process contains pointers to struct files in the file table.
What happens if two different processes open the same file? They have two different entries in file table because they need to read and write independently at different offsets. However, the file table entries point to the same inode.
On the other hand, when P forks C, both file descriptors will point to the same struct file (ref is increased) and the offsets are shared. The reference count of struct file is number of file descriptors that point to it. Similarly, an inode also has such a reference number.
The in-memory inode is almost a copy of the disk inode, stored in the memory for open files. All of these in-memory inodes are stored in a fixed size array called inode cache icache. The in-memory has a ref that the disk inode doesn’t have. It stores the number of pointers from the file table entries. This is different from the nlink which counts the number of files that point to this inode in the disk. A file is cleaned up on the disk only when both ref and nlink are zero.
Cleaned up from memory or disk?
inode functions
- Function
iallocallocates a free inode from the disk by looking over disk inodes and finding a free on for a file. - Function
igetreturns a reference counted pointer to in-memory inode inicacheto use in struct file etc. This is a non-exclusive pointer which means the information inside inode structure may not be up to date. - Function
iputdoes the opposite of the above function. - Function
ilocklocks the inode for use by a process, and updates it information from the disk if needed.iunlockis the opposite. - Function
iupdatepropagates changes from in-memory inode to on-disk inode.
ilockupdates from disk? Also, why not up to date info? All share pointers right?
Inode also has pointers to file data blocks. The function bmap returns the address of the nth block of the file. If it’s a direct block, we read from the inode. Otherwise, we read indirect block first and then return block number from it. This function can allocate data blocks too - if n-th data block of the file is not present, it allocates a new block on the disk, writes it to the inode and returns the address. Function readi/writei are used to read/write file data at a given offset. They call bmap to find the corresponding data block. Additionally, bmap uses balloc to allocate a data block in the disk, and bread to read the data blocks.
Directory functions
We have two additional functions for directories:
- Directory lookup - Read directory entries from the data blocks of the directory. If file name matches, return pointer to the inode from
icache. -dirlookup - Linking a file to a directory - Check file with the same name does not exist, and add the mapping from file name to inode number to the directory. -
dirlink
Creating a file
We locate the inode of the parent directory by walking the filepath from the root. Then, we look up the filename in the parent directory. We return the inode if the file already exists. Otherwise, we allocate a new inode for it, lock it, and initialize it. If the new file is a directory, we add entries for . and ... Otherwise, we link it to its parent directory. All of this is done in the create function.
Is create a system call?
System call - open
We get the arguments - filename and the mode. We create a file (if specified) and get a pointer to its inode. Then, we allocate a new struct file in the ftable, and also a new file descriptor entry in struct proc of the process pointing to the struct file in ftable. Finally, we return the index of new entry in the file descriptor array of the process. Note - begin_op and end_op capture the transactions for the log file.
System call - link
This function links an existing file from another directory with a new name (hard linking).
Is different directory necessary?
We get the pointer to the file inode by walking the old file name. Then, we update the link count in the inode. Once we get the pointer to the inode in the new directory, we link the old inode from the parent directory using a new name.
Do we need a new filename? Do we need a different directory?
System call - fileread
The sys_read system call calls fileread. This is a general template for the other system calls. For example, file read does the following -
- Get arguments (file descriptor number, buffer to read into, number of bytes to read)
- Fetch inode pointer from the struct file and perform read on inode (or pipe if the file descriptor pointed to pipe).
What pipe?
- Function
readiuses the functionbmapto get the block corresponding to the nth byte and reads from it. - Offset in struct file is updated.
Summary
- Disk is organized as inodes, data blocks and bitmaps
- The in-memory organization consists of file descriptor array which points to struct file in file table array which in turn points to in-memory inode in the inode cache.
- A directory is a special file where data blocks contain directory entries (filenames and corresponding inode numbers).
- Updates to disk happen via the buffer cache***. Changes to all blocks in a system call are wrapped in a transaction and are logged for atomicity.
References
Enjoy Reading This Article?
Here are some more articles you might like to read next: